Important note: this blog contains a brief summary of the developments of the Machine Learning Model Development using AutoML use case. For more details and information, please access the complete official document of this work.
This blog outlines the development and deployment of a machine-learning solution aimed at predicting credit card fraud. By leveraging AutoML and Google Cloud services, the solution provides a robust framework for addressing fraud detection, ultimately helping companies safeguard their financial interests.
Business Goal and Machine Learning Solution: Identifying the Business Question/Goal
In this section, we address the business question of predicting credit card fraud cases from a set of features. This allows companies (such as credit card or insurance companies) to anticipate fraud cases and take preventive actions. By deploying a machine learning model to predict fraud cases, the company can enhance its fraud detection capabilities and improve financial outcomes.
In this blog, we address the critical business need of predicting credit card fraud. This is vital for companies like credit card and insurance companies to proactively identify and mitigate fraud cases, ensuring financial stability and security.
Machine Learning Use Case
The focus is to develop a machine-learning solution that accurately predicts credit card fraud. This involves presenting a complete machine learning workflow, from data exploration to model deployment. The goal is to provide a predictive classifier model that can forecast credit card transaction outcomes (fraud or not fraud) based on a given set of features.
How the Machine Learning Solution Addresses the Business Goal
The proposed solution is a predictive classifier model, trained using AutoML and deployed on the Google Cloud Model Repository. This model will receive requests and provide forecasts for credit card transaction outcomes, enabling the company to act swiftly on predicted fraud cases and enhance their financial results.
Implementation Details
Data Used
The data for this demo consists of two datasets:
- Training Dataset: Contains balanced cases of fraud and non-fraud.
- Test Dataset: Used to validate the model.
Both datasets were built from the original Raw creditcard.csv file provided by Kaggle.
Workflow and Model Development
The workflow includes:
- Data Exploration: Analyzing the dataset to identify relevant features and necessary transformations.
- Model Training: Using AutoML to train a predictive classifier model.
- Model Deployment: Deploying the trained model to Google Cloud Model Repository.
The objective is to illustrate the implementation of a complete machine-learning workflow to achieve accurate predictions.
Steps in Machine Learning Model Development
The use case involves presenting a complete machine learning workflow, from data exploration to model deployment, to predict the outcome of credit card transactions (fraud or not fraud). A predictive classifier model, trained using AutoML, is deployed on the Google Cloud Model Repository to an endpoint for making online or batch predictions.
Expected Impact on Business Goal
By implementing a machine learning solution to predict credit card fraud, companies can proactively address fraud cases, thus safeguarding financial assets and improving overall financial health.
Data Exploration
Data Exploration Overview
For effective data exploration, partners should:
- Describe the data exploration performed
- Explain how modeling decisions were influenced by this exploration
Key Steps in Data Exploration
- Identify Variables: Determine each variable in the datasets (train and test).
- Data Types: Check and adjust data types if necessary.
- Column Elimination: Identify and discard irrelevant columns.
- Transformations: Apply necessary transformations to variables.
- Correlation Analysis: Analyze correlations to decide which variables to keep.
- Missing Values: Identify and address missing values.
Data Exploration Process
- The original creditcard.csv dataset was copied to a Cloud Storage bucket.
- Data types were checked and found suitable.
- The distinct values of each column were analyzed, with no missing data identified.
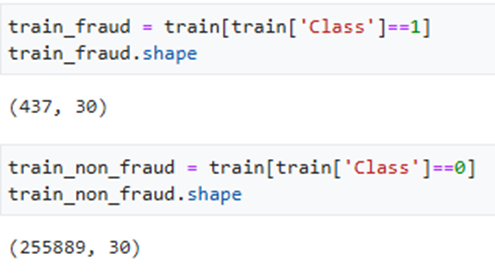
- Notable skewness was found in the response variable (Class), which had very few fraud cases.
- Feature V2 was discarded due to its significant correlation with the amount variable.
Key Findings
- Correlation: A significant correlation between V2 and the amount led to V2 being discarded.
- Missing Values: No missing values were found in the dataset.
CODE SNIPPET:

- Class Distribution: The response variable (Class) distribution was highly unbalanced, with rare fraud cases.
CODE SNIPPET:
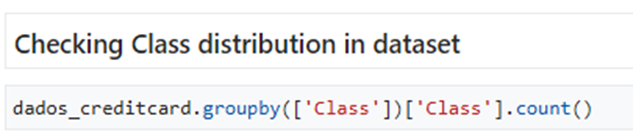

Figure 1: Countplot of response Class variable
Feature Engineering
Feature Engineering Overview
Feature Engineering Steps
- Eliminate Feature V2: Remove V2 from train and test datasets.
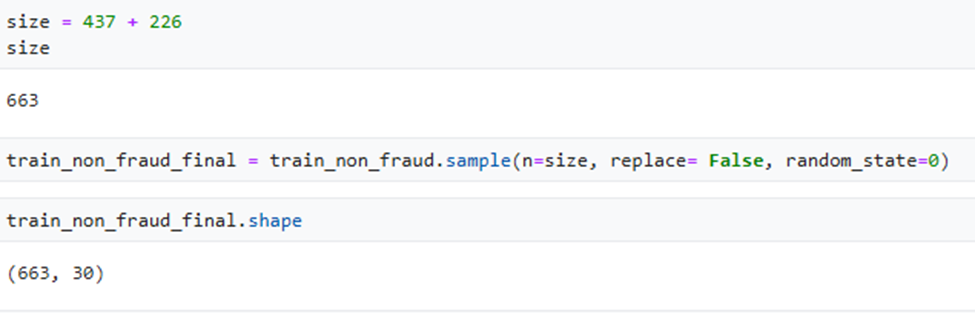
- Train-Test Split: Create a balanced training dataset (90% of fraud cases retained) and an unbalanced test dataset (10% of original data).
Feature Engineering Details
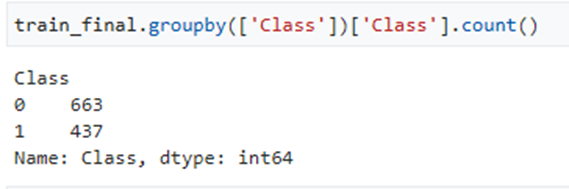
- The training dataset was balanced with 1100 rows, ensuring a balanced class variable.
- The test dataset consisted of 10% of the original unbalanced data.
CODE SNIPPET:
Data Security and Privacy in Cloud Storage
Data Security and Privacy Measures
- The dataset resides in a Cloud Storage Bucket within a specific project linked to a specific service account.
- Only individuals with proper IAM credentials can access the project and dataset.
- The dataset is public and contains no sensitive information, so no data encryption was necessary.
Data Preprocessing and Final Data Strategy
Preprocessing Steps
All preprocessing steps were aligned with the feature engineering steps previously mentioned.
Machine Learning Model Design and Selection
Model Selection
For Demo 3, a predictive classifier was trained using AutoML, with default options ensuring automatic model training and selection.
Used Libraries
No specific libraries were used for model training and selection, as AutoML handled these processes.
Model Selection Process
AutoML handled all aspects of model training, validation, and selection automatically.
Figure 2: Steps in training classifier model in Auto ML
In the figure above, we chose the Other option.
Figure 3: Steps in training classifier model in Auto ML
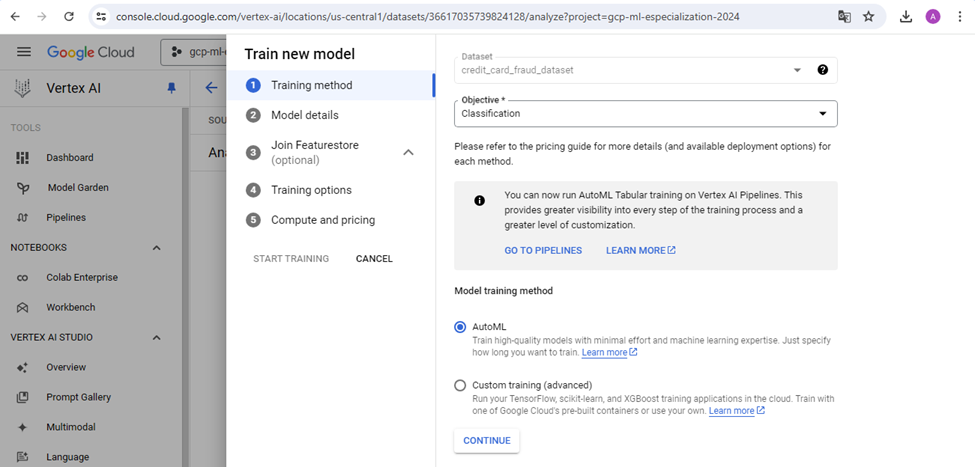
Figure 4: Steps in training classifier model in Auto ML
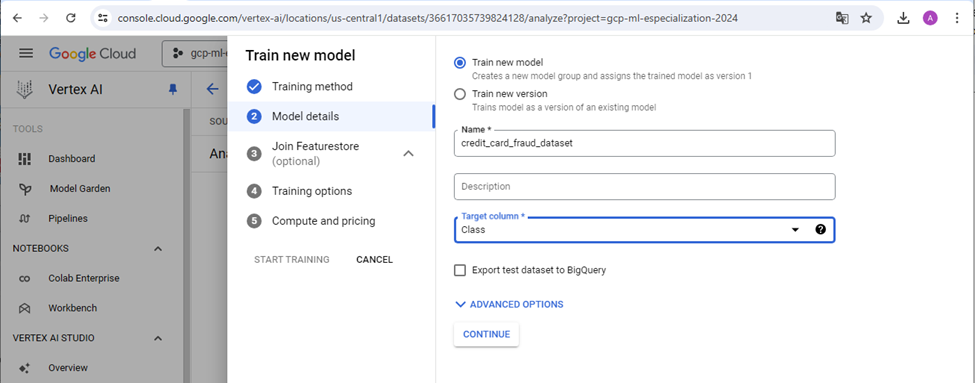
Machine Learning Model Training and Development
Dataset Sampling and Training Configuration
The train-test split was designed to balance the training dataset while leaving the test dataset unbalanced.
Adherence to Google’s Machine Learning Best Practices
The development followed Google's ML Best Practices, utilizing recommended products and tools:
- ML Environment Configuration: Used AutoML.
- ML Development: Utilized Cloud Storage and AutoML for model development.
- Data Processing: Used Pandas DataFrames in Vertex Workbench instances.
- Operational Training: AutoML managed all model training and deployment.
- Artifacts Organization: Stored resources in Cloud Storage within a specific project.
- ML Environments: Utilized AutoML functionalities in the Vertex AI environment.
Machine Learning Model Evaluation and Performance Assessment
Model Evaluation Metrics
AutoML provides a comprehensive set of metrics and performance indicators. For the final model in the training dataset, the recommended metric is the Area Under the ROC curve due to the slightly unbalanced nature of the training data.
Model Performance
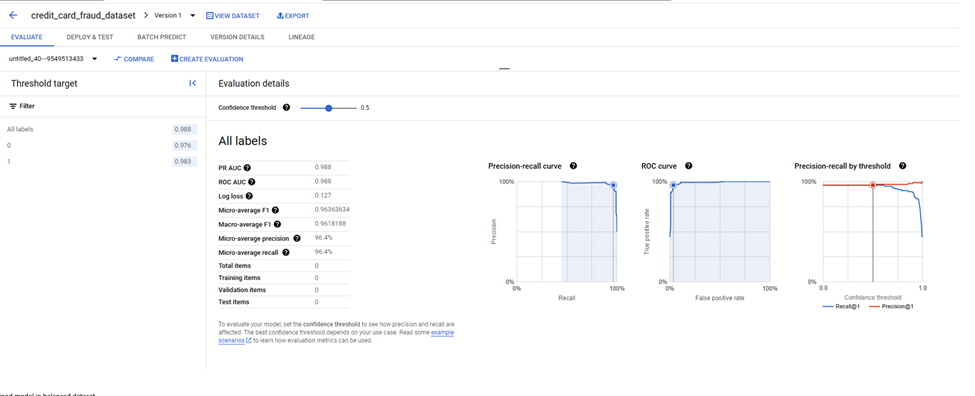
The final classification model achieved the following:
- Accuracy: Correctly predicted all non-fraud cases and 91% of fraud cases in the training set.
- Feature Importance: Feature V14 was the most significant in explaining the response variable (Class).
- Performance Metrics: Included precision-recall, ROC, and precision-recall by threshold curves.
Overall, the machine learning workflow demonstrated how to implement a comprehensive solution to predict credit card fraud, adhering to best practices and optimizing model performance.
Figure 5: Final classification model performance on training set
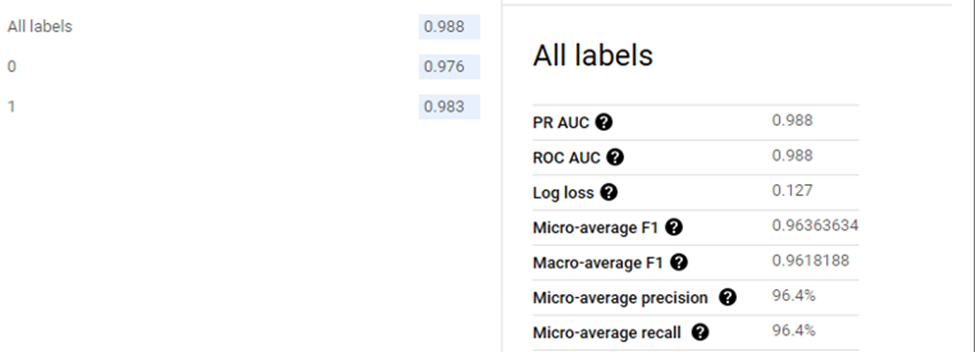
Figure 6: Final model Confusion matrix
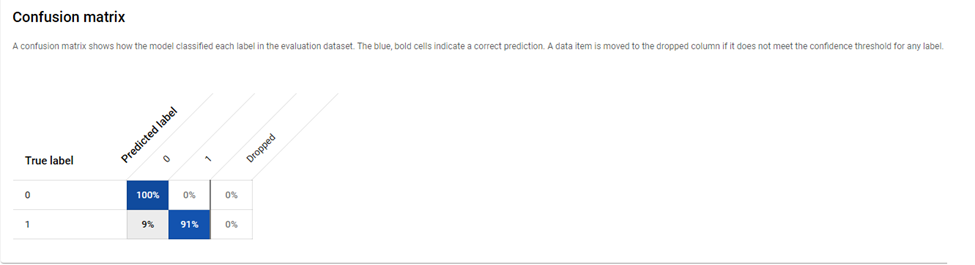
We see by the presented confusion matrix that the final model (provided by AutoML) predicted correctly all non-fraud cases and 91 % of the fraud cases in the train set. This is a classic symptom of overfitting the data.
Figure 7: Final Model Feature Importances
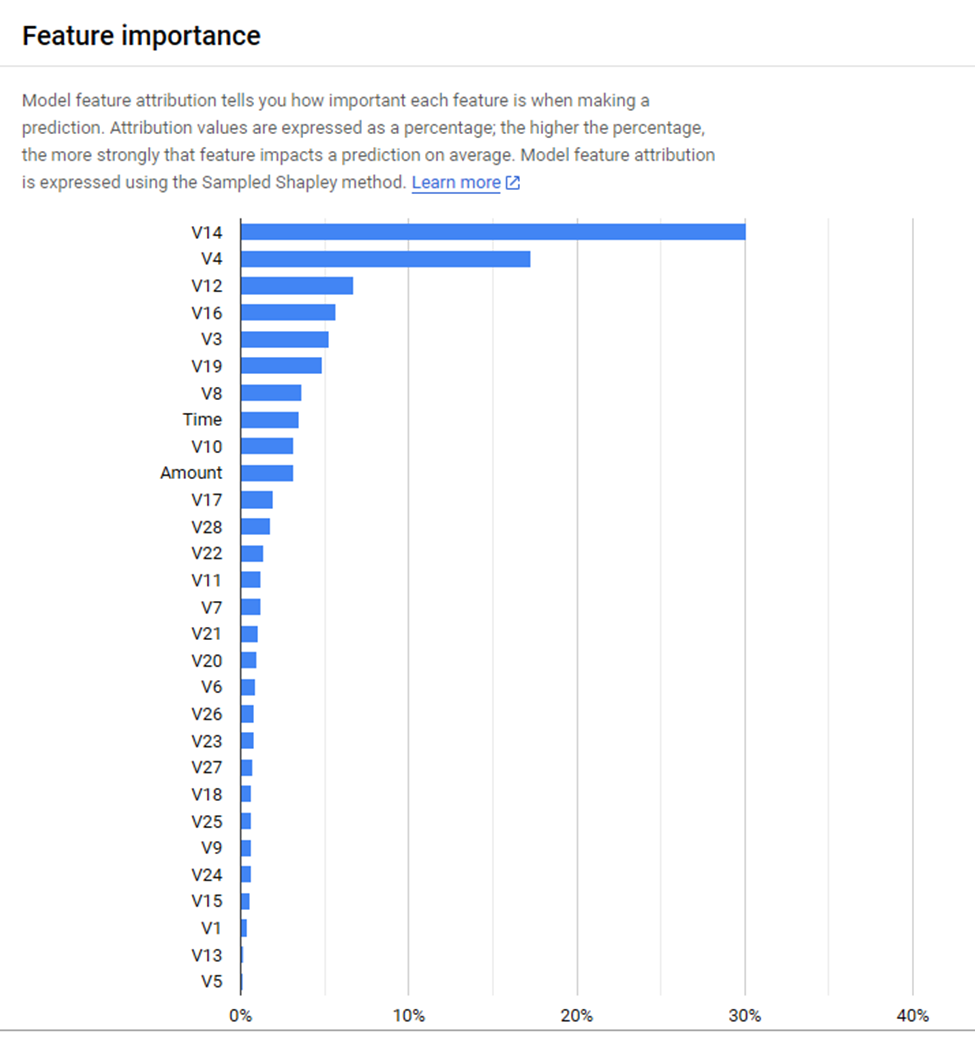
From the figure above we see that feature V14 was the most important feature in the explanation of response variable Class.
Figure 8: Final model Precision-recall, ROC, and Precision-recall by threshold curves.