
Ever suffered from information overload? Finding simple pieces of information can feel like a daunting task. With all the choices and sources of information available on the internet today, it's absolutely necessary to find a way to prioritize, filter, and professionally deliver appropriate information. Recommender systems resolve this problem by searching inside large amounts of generated information to provide users with personalized services, information, and content.
In very simple words, a recommender system is a subclass of an information filtering system that predicts the "preference" that a user would give an item.
Main Types of Recommender Systems
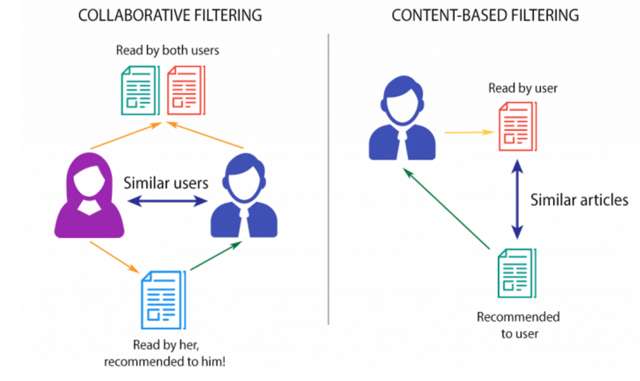
Collaborative Filtering
Collaborative Filtering (CF), filters information by using the recommendations of other individuals. It's based on the logic that people who agreed in their assessment of some items in the past are expected to come to the same consensus again in the future. An individual who desires to read a book for instance, may ask for recommendations from friends. The recommendations of certain friends who have similar interests are trusted more than recommendations from others. This information is used in deciding which book to read.

1
Advantages:
-
-They can be useful for any domain and in addition to domains
-CF engines work best when the user space is large
-The selling point of CF engines is that they're totally independent of any machine-readable representation of recommended objects, and work well for complex objects such as music and movies, where differences in taste are accountable for much of the variation in preferences (Good, Nathaniel, et al)2.
Drawbacks:
- -CF engines suffer from the "new item" problem - until an item has had some interaction with users, there is a lack of data to properly classify and recommend it.
Content Based Recommender System
A Content-Based (CB) filtering system selects items based on the correlation between item content and user preferences as opposed to a CF system which chooses items based on the correlation between people with similar preferences (Meteren, et. al)3.
4
Advantages:
- Does not require data from other users
-No cold-start or sparsity problems
-It can provide recommendations to users with unique tastes
-It can recommend new and unpopular items
-No first-rater problem
-Can provide explanations of recommended items by listing content-features that caused an item to be suggested
Disadvantages:
- -Finding suitable features is difficult. For example: images, movies, and music
- -Recommendations for new users are difficult because it's not possible to build a user profile
- -Overspecialization – never recommends items outside the user’s content profile
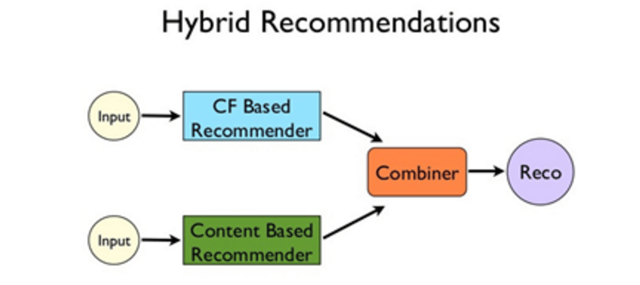
Hybrid Methods
Hybrid recommender systems combine two or more recommendation methods, which results in better performance with fewer of the disadvantages of any individual system. Typically, CF is combined with another method to help avoid the ramp-up problem. For example, a weighted hybrid recommender is one in which the score of a recommended item is calculated from the outcomes of all the available recommendation methods present in the system. So then, the simplest combined hybrid would be a linear combination of recommendation scores (R. Burke)5.
 A Success Story
A Success Story
Are recommender systems useful? In 2006, Netflix offered a one million dollar prize for anyone who could advance their recommender system algorithm by a minimum of 10%. There were over 44,000 entries from over 41,000 teams on behalf of approximately 51,000 contestants. On 21 September 2009, the grand prize of US$1,000,000 was given to the BellKor's Pragmatic Chaos team who used tiebreaking rules (S. Lohr)6. By decreasing the error of their recommender system, Netflix was able to boost business and create profit tremendously. It's clear, then, the value that a great recommender system brings for users. But how can we create them?
Building A Recommender System Using Azure Machine Learning (AML) Studio
After learning a bit about recommender systems, it's time to build a simple one using AML. For this, we need to have an AML account, which is free, and some data.
Data Set
MovieLens 1M Dataset7
The MovieLens dataset is perfect for our purposes - it is a stable benchmark dataset, composed of 1 million ratings from 6000 users on 4000 movies and released 2/2003. GroupLens Research has collected and made rating data sets available from the MovieLens web site (http://movielens.org). The data sets were collected over various periods of time, depending on the size of the set. These files contain about 1,000, 000 anonymous ratings of approximately 3,900 movies made by 6,040 MovieLens users who joined MovieLens in 2000. All ratings are contained in the file "ratings.dat" and are in the following format:
UserID::MovieID::Rating::Timestamp
-UserIDs range between 1 and 6040
-MovieIDs range between 1 and 3952
-Ratings are made on a 5-star scale (whole-star ratings only)
-Timestamp is represented in seconds since the epoch as returned by time (2)
-Each user has at least 20 ratings
The Step of Building Recommender System in AML
Uploading the Required Dataset to AML
First, extract the downloaded file and select rating.dat from the listed file. The format of this file is “dat”, so we need to convert this file to a CSV format. After that, select the DATASETS module from the AML main menu, click on new icon on the bottom-left corner of the page, then upload the converted file from the local storage of your PC to AML. While uploading, select the file type as CSV without a header, and name that file “rating”. It will take some time to upload.
Create a Blank Experiment in AML
In this step, we will create an experiment in our default workplace. Go to the experiment tab, and then create a blank experiment like below:
Name your experiment at the top of the page. For example: “Recommender Systems”.
Importing the Dataset in the Experiment
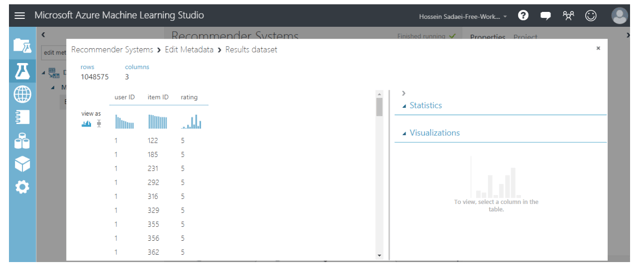
From the left hand-side menu, open saved datasets and drag your uploaded dataset ,i.e., “rating.csv” from my datasets. You can see some information about this file by right-clicking on the reader module and selecting Visualize from the menu.
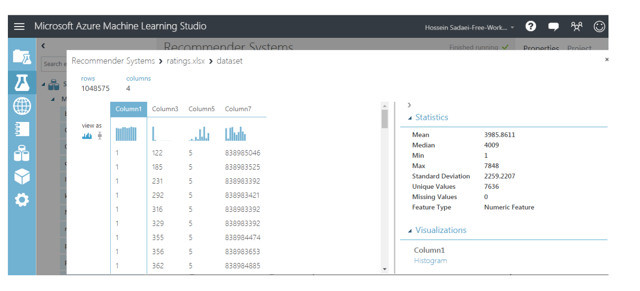
As shown in the picture above, there are 4 columns in the dataset with 1,048,575 rows. The first column is related to the user ID, the second column is for the movie ID, the third column corresponds to ratings, and the last column is for the timestamps. In this experiment, we will only be using the first three columns.
Select Column in the Dataset
We can select the three required columns using the specific module in AML called “Select Column in Dataset”. Just search the name of this module in the search box on the top-left of your experiment, and then drag and drop it into your experiment environment in the provided space.
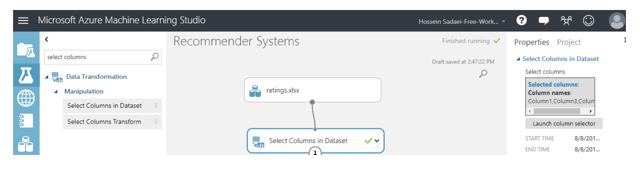
Then, select this module and click on “Launch column selector” in the right hand side panel at the same time. Next, select corresponding columns related to user ID, movie ID, and rating while excluding timestamp as shown below:
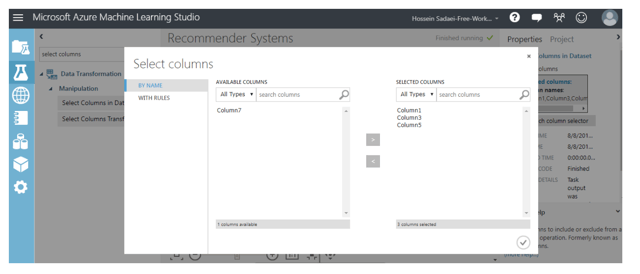
Edit the Metadata
Now, it's time to give proper names to the already selected columns and define the data type. In order to do this, perform a search for the module named “Edit Metadata”. We'll do the whole procedure using two of these modules in two steps. First, drag Edit Metadata from the left-hand side menu, and after selecting that, try to configure it as shown in right-hand side panel of the figure below:
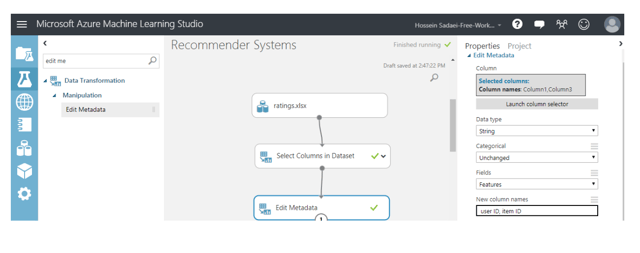
Next, select two columns and change their type to string. They're also selected as features. Then, we have to change the name of “Edit metadata” to “rating” in the next column as well as change its type to float and field to label. See the snapshot below:
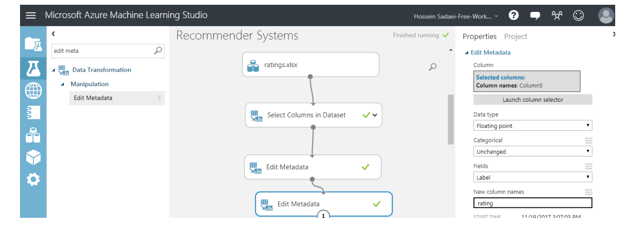
In order to ensure that everything is going smoothly, we can run what we've developed so far by clicking on the ‘Run’ button on the bottom horizontal menu. The red tick next to each module shows that the running of that part has been finished with no error. The output can be seen by right-clicking on the module added last, and then visualizing that content. The output should be something like this:
 Splitting the Dataset Into Training and Testing Sets
Splitting the Dataset Into Training and Testing Sets
Now that the data processing part is finished, everything is prepared for building the recommender system. While building any machine learning model, including the current one, we need to make sure that the model is valid for training and testing data. So, in this step, we need to split the dataset into training and testing datasets. For this reason, we can add a “Split Data” module from AML, and configure it as follows:
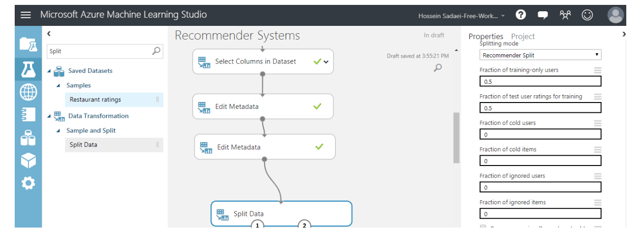
Note: Be informed that these configurations are unique to recommender data and control how values are divided among training and test sets, or among training and scoring sets. In all cases, you specify a percentage represented by a number between 0 and 1. The explanation of configurations is as follows:
- -Fraction of training only users: Specify the fraction of users that should be assigned only to the training data set. This means the rows would never be used to test the model.
- -Fraction of test user ratings for training: Specify that some portion of the user ratings you have collected can be used for training.
- The left hand side output of this module corresponds to the training dataset, and the right hand side port relates to the testing dataset.
Training the Model
After splitting data into training and testing sets, it's time to select a proper model and then train the model. Fortunately in AML, we can easily train a recommender system by using the “Train Matchbox Recommender” module. The Train Matchbox Recommender module reads a dataset of user-item-rating triples and, optionally, some user and item features. It delivers a trained Matchbox recommender. You can then use the trained model to generate recommendations, find related users, or find related items by using the Score Matchbox Recommender module. More information on how this model works can be found on the AML official website in this link. We also need to add a “Score Matchbox Recommender” for prediction purposes as well as an “Evaluate Recommender” to evaluate and validate the model. These modules must be connected as shown in the snapshot below:
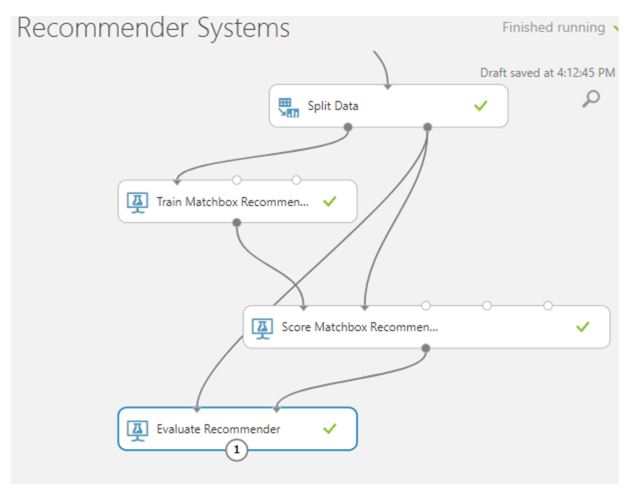 Running the Model
Running the Model
Now that the building of the model is finished, it's time to run the model and test its accuracy. Simply save the model and then run it. The whole model should be similar to the following model:
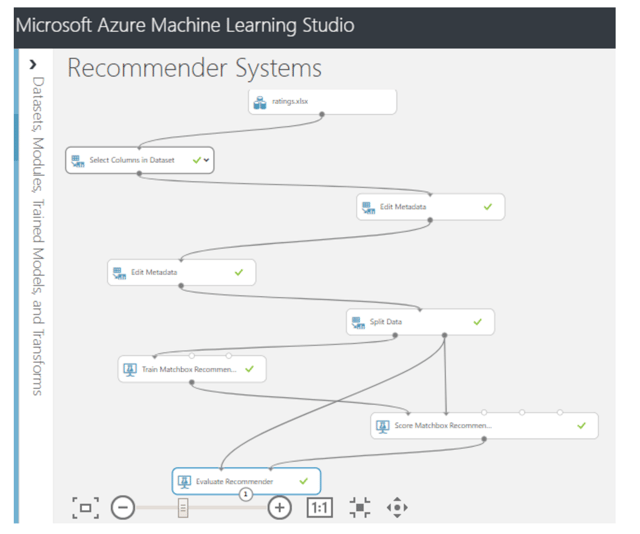 Evaluating the Model
Evaluating the Model
After running the model, we'll have following results in the “Evaluate Recommender” model.
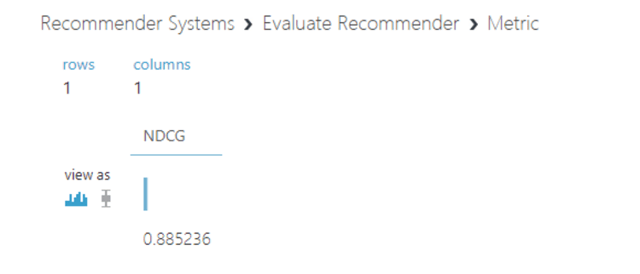
So, by using this simple model we were able to reach 88% accuracy with the testing data set, which isn't too bad. If we want to boost the results, we need to use a more advanced model and datasets (e.g., hybrid models and other datasets available in a downloaded bundle).
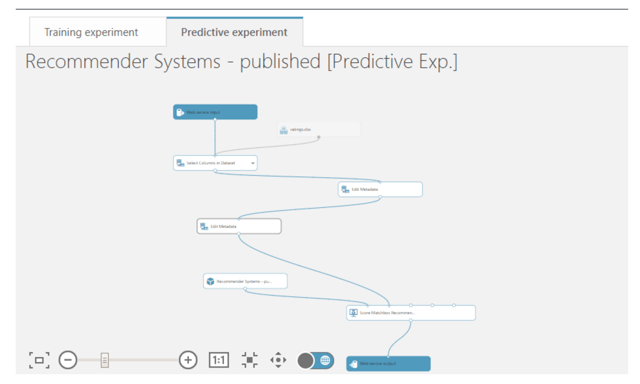
Creating Web Services
Now we've finished the model development process and can create a web service to use this model in real application. In order to setup a web service option, simply select the “Predictive Web Service” button. AML will automatically complete all required tasks and create the model for you, ready to be deployed as a web service. The output after completing this should be similar to below:
 Deploying as a Web Service
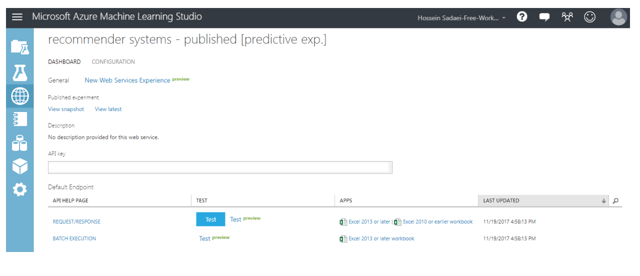
Deploying as a Web Service
For deploying the model, it's better to run the experiment one more time and then deploy the web service. The output should be like this:
 Summary
Summary
In this blog, we employed AML to build a recommender system using data related to movie ratings. In the end, we were able to reach 88% accuracy in the testing set. Moreover, we created and deployed a web service as well.
References
1 "1 Collaborative Filtering Rong Jin Department of ... - SlidePlayer." http://slideplayer.com/slide/5005595/. Accessed 21 Nov. 2017.
2 "Combining collaborative filtering with personal agents for better ...." 18 Jul. 1999, http://dl.acm.org/citation.cfm?id=315352. Accessed 21 Nov. 2017.
3 "Using Content-Based Filtering for Recommendation - CiteSeerX." http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.25.5743&rep=rep1&type=pdf. Accessed 21 Nov. 2017.
4 "How do Recommendation Engines work? And What are the Benefits?." https://www.marutitech.com/recommendation-engine-benefits/. Accessed 21 Nov. 2017.
5 "Hybrid Recommender Systems: Survey and Experiments ... - CiteSeerX." http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.88.8200&rep=rep1&type=pdf. Accessed 21 Nov. 2017.
6 "A $1 million research bargain for Netflix and maybe a model for others." 21 Sep. 2009, http://www.nytimes.com/2009/09/22/technology/internet/22netflix.html?pagewanted=all. Accessed 21 Nov. 2017.
7 "MovieLens 1M Dataset | GroupLens." https://grouplens.org/datasets/movielens/1m/. Accessed 21 Nov. 2017.




