
The purpose of this article is to discuss data, understand the most common terms in this field, and the significance of each one. We will also delve deeply into the concept of data as the "new oil". If you are a beginner in this field, this article will be extremely beneficial for you. If you are already in the field, I believe this article can reinforce your passion for this rewarding work area and enhance your understanding of some of the concepts that will be discussed.
Why is Data So Important Today?
In its informational sense, data refers to the act of recording an attribute of an entity, object, or phenomenon. In other words, it is the recording or imprinting of characters or symbols that hold meaning on some document or physical medium.
There is an intriguing statistic that states that each person creates 1.7 MB of data every second. This statistic is daunting, yet very real. Data has always existed. For instance, when letters were invented, in addition to the text of its composition, other data was added about the sender's name, the recipient, and the location to which the letter would be sent. Thus, data has been a reality in everyone's lives for a very long time.
However, nowadays, due to advancements in computing, it has become more viable and easier to record and store data. With a simple Excel spreadsheet, you can create a database of anything. Technology has provided greater scalability for all of this. Therefore, if data was already very present in our daily lives, now it truly is. It's worth noting that with this storage possibility, the capacity for processing and analysis also began. This final ingredient has made the data sector even more relevant, as there is no point in merely storing data for the sake of storing it. Processing and analyzing data reveals the great secret of data: knowledge.
The DIKW Pyramid
Here, it is worth introducing the DIKW Pyramid (also known as the Knowledge Pyramid). The Knowledge Pyramid is structured into four parts: data, information, knowledge, and finally, wisdom.
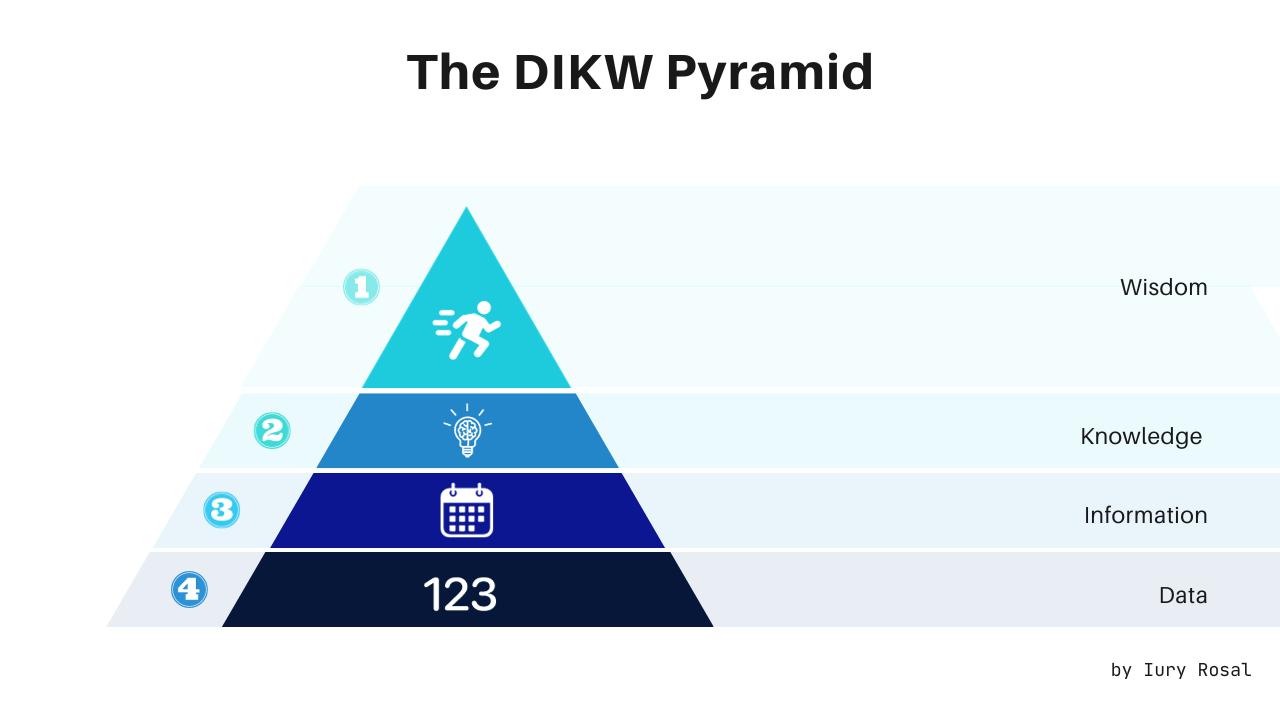
To make it easier to understand, let's take an example. Initially, we record a number, for example, 12012000. This is just data. In the end, just having this is not enough, as we don't know where to go because we don't understand what is behind this value. Data is a collection of facts in a raw or unorganized form, such as numbers or characters. Now, imagine that we assign this number to an individual's date of birth, with a format in day, month, and year (01/12/2000). Now, we have information. Information adds context and meaning to data. Information is simply an understanding of the relationships between parts of data, or between parts of data and other information.
Understanding that the date symbolizes an individual's moment of birth, we can extract valuable information from it. By comparing the birth year with the current year, we can estimate the individual's age. From this age, we can attempt to infer additional information about the individual, such as predicting their income (assuming we have the necessary conditions and historical data). This gives us knowledge. Knowledge is the proper use of information. When we not only see information as a collection of facts but also understand how to apply it to achieve our goals, we transform it into knowledge. For instance, if we discover that individuals aged 18–25 have an average income of R$4000, this becomes our knowledge, or as we call it, "insight".
Imagine our company has a product that benefits and targets people with an average income of less than R$5000. Knowing that people aged 18–25 have an average income of less than R$5000, we can target this group with our product and direct campaigns towards them. This strategy can improve prospecting productivity and increase the company's sales. This application of knowledge is wisdom. Wisdom, the pinnacle of the DIKW hierarchy, is achieved by answering questions like "Why do something" and "What is best". In essence, wisdom is knowledge applied in action.
Once we understand this pyramid theory, it becomes clear that the ultimate goal is to reach the stage of wisdom, as it enables productivity and profit gains. With wisdom, individuals and corporations can make safer and more accurate decisions. Technological advancements have made it increasingly possible for people and companies to attain this level of wisdom. Although it's not an easy path, the computational power and accessibility we have today make it much more achievable than in previous years. Tools like Excel allow us to analyze and study stored data, not to mention the numerous other computational tools that enable diverse ways of processing, treating, and analyzing data in various situations. Moreover, we now have more stored data than ever before. To reach the stages of knowledge and wisdom, we need a large amount of data for more accurate analysis. In my opinion, this combination of factors explains the data explosion.
The 3 C’s of Data
To deepen our understanding of data, let's now discuss the 3 C's of Data: Capture, Curate, Consume. We can draw an analogy to this process with a generic production model for any raw material. As we mentioned oil at the beginning of this article, we will use it as an example.
Data is valuable, just like oil, but if it's not refined, it can't really be used. Oil must be transformed into gas, plastic, chemicals, and a multitude of other products to create a valuable entity that drives profitable activities. Therefore, data must also be broken down, analyzed, and transformed to have value.
Capture
Capturing data is the initial phase, as it is the resource we need to seek information, knowledge, and ultimately, wisdom. There are several ways to capture data: we can capture it through forms, extract it from a web page or a certain document, or purchase already developed databases, among others.
At this stage, it's crucial to address questions such as: "What data will we collect?", "What data can we generate?", "What data might be useful in the future?", and "Is there data we should seek out and/or purchase?”
Let's take this opportunity to introduce some concepts:
- Internal data: Data that has a direct relationship with the company/person in question. Examples include sales information, documents, contracts, images, product/service information, etc.
- External data: Data that has no direct relationship with the company/person, such as data purchased or extracted from an external webpage.
Within these two groups, we have:
- Structured data: Data that has well-defined, rigid structures, thought out before the existence of the data that will be loaded into that structure. For example, a date field already has D/M/Y formatting, and we know that it is a date. This data is stored in a specific column designated for it in a table.
- Unstructured data: This type of data does not have well-defined, aligned, standardized structures, and can be composed of several different elements within a whole. Examples include videos, audio, free texts, images, etc.
- Semi-structured data: This is partially structured data. For example, an email has the subject, recipient, and sender parts that we can consider as structured, while the body of the email is less structured.
Interestingly, unstructured data comprises around 80% of all existing data in the world, precisely because it is created from the daily use of technologies in society, such as text messages, digital documents, and WhatsApp/Telegram audios, among others. Unstructured data also requires the most effort in this capture and processing process, precisely because it is not structured.
Curate
After collecting and capturing data, we must verify its veracity and reliability. This involves preparing, processing, and treating the data. In the case of unstructured or semi-structured data, we need to structure it. We must handle invalid, null, inconsistent, duplicate, or incorrectly formatted data. This process is one of the most time-consuming for data professionals and also one of the most important. After all, cleaning, processing, and validating data is the step that allows the collected data to be used for analysis, modeling, and studies, thereby facilitating the ascent of the DIKW pyramid.
Consume
With the data cleaned, validated, structured, and ready, we can now use it. But what can we do with it?
- Data Analysis: This involves generating reports with visualizations (Data Visualization) with the intention of generating knowledge to assist in decision-making or to facilitate the understanding of a certain aspect of the business. For example, using customer data, analyses can be carried out to help the marketing department in targeting campaigns and prospecting actions.
- Machine Learning: From the data, we can build models that can also help in decision-making or influence the productivity of a given sector. For example, based on a history of customers who did or did not close a contract with the organization, we can build a model that predicts for a new customer the probability of closing a contract or not. This can help commercial managers to determine whether the lead (potential customer) is a cold or hot contact, not just subjectively, but also to direct better actions depending on the position the lead is in.
These examples of data consumption can be applied both internally to the organization and to generate marketable products for the organization. The organization may also sell this data or even provide related services that involve data security, storage, validation, and/or processing.
Data Storage
As previously mentioned, data storage is essential for enabling the consumption phase. Given its importance, let's now examine some relevant terms related to this.
Database
A database is a type of organization where you store your data, aiding in maintaining the organization, security, reliability, and accessibility of the data. An example of a database would be an Excel table, in which you can distribute the data into columns with predefined formatting and rules for recording it. From this Excel table, you can easily use this data in other environments, such as loading it into Power BI or within a Python script to generate an analytical report.
Database Management System (DBMS)
A DBMS is software that creates, defines, and manages various databases. For instance, PostgreSQL is a DBMS that allows you to manage several databases, with rules and procedures to facilitate database maintenance, as well as data organization. Currently, there are several programs responsible for database management that are very similar to each other, with some specific differences.
Now, let's envision a generic structure of a company with its various departments: projects, human resources, marketing, finance, and administration. Each department has its processes and, consequently, generates data related to these processes. Let's deepen our discussion about data storage by considering how to ensure organization and facilitate the maintenance of the company's data so that all departments benefit from the data area.
Data Silos
Each department of the company will store data in a specific area designated for that purpose. For example, the marketing department will have a specific place to store marketing data, and the same applies to other departments.
Here we use the so-called Data Silo, which is an isolated structure (an isolated database), with an independent collection of data, accessible only by one part of the organization. Imagine an industry that produces several raw materials; we have a silo for each raw material. After all, it wouldn't make sense to mix rice grains with bean grains initially. Similarly, it wouldn't make sense to mix customer data with data from the company's employees in the same place, from the beginning.
.png?width=1280&height=720&name=The%20DIKW%20Pyramid%20(1).png)
However, using just this structure can cause many problems, as we will have a lot of decentralized data and there is a greater difficulty in maintaining and scaling the use of data. In addition, they would hardly store large data histories, as they have a more operational focus.
Here we can include the term Data Store, which would be a collection of data (not just structured) with a variety of formats for a specific purpose, which normally does not fit within storage structures (Data Warehouse, Data Lake). The Data Silo works, depending on the context, like a Data Store.
Data Warehouse
Well, we have the data isolated from the departments. However, imagine how complex it would be to always have to access the data separately. To carry out any analysis or any machine learning procedure it would be a huge expenditure of energy to load data from different Data Silos, as well as standardize and process them.
The concept of Data Warehouse is precisely to provide this unification: it would mean having a connection with all these data silos, having a central repository (a set of central databases) with integrated and standardized data, always being fed with new data and storing the data history. Standardization becomes fundamental, as the same thing may have different concepts between company departments. For example, for marketing, the company's revenue is equivalent to the total value of sales, whereas for finance, revenue is the result of sales minus costs. With standardization, this allows concepts to be aligned with company metrics, thus facilitating a single analysis for everything. The fact that all data and history from all departments are in the same place allows for better maintenance, management, and loading of this entire data load.
.png?width=1280&height=720&name=The%20DIKW%20Pyramid%20(2).png)
It's worth emphasizing that the intention is not for marketing to use the Data Warehouse to retrieve information from a customer to formalize a contract. For this marketing operation, the commercial manager will use the Marketing Data Silo. The Data Silo is aimed at more operational use, while the Data Warehouse aims to be something parallel to the company's operations. Thus, the final intention is to use it to develop data products for the company itself, to facilitate the generation of analyses, reports, and modeling to boost the company's operations and assist in decision-making.
Data Lake
Data Lake is a type of repository that stores large and varied sets of raw data in a native format. With data lakes, you get an unrefined view of the data. The term “data lake” was created by James Dixon, CTO at Pentaho. It is appropriate to describe this type of repository as a lake because it stores a set of data in its natural state, like a body of water that has not been filtered or contained. Data flows from multiple sources into the data lake and is stored in its original format.
.png?width=1280&height=720&name=The%20DIKW%20Pyramid%20(3).png)
The difference between a Data Lake and a Data Warehouse is that a Data Warehouse stores structured data with the intention of facilitating reporting, and the data already has a destination. The Data Lake stores data in its raw form that does not yet have a designated purpose. For example, the Data Warehouse will have a table with structured customer data: imagine a table with the customer's name, customer CPF, contract value, employees allocated to the project, etc. The Data Lake will have things like the project contract document. This is the difference between these two structures. It is worth noting that the Data Lake can have structured data, but this is not the rule. The intention of the Data Lake is to store the data in its raw form, without requiring a transformation before loading it into the structure. The similarity between these structures is that they are centralized structures (which work in parallel and independent of the company's operations), with the idea of storing a long-term history and thus having a large arsenal of data.
What is best to use? Well, a Data Warehouse is efficient when you already have an idea of the reports that will be generated and the purposes of the data. When you don't have this in mind, but you want a central information structure, the Data Lake is the best solution and the fastest too, as there is no need to worry about carrying out the data transformation process. But it is worth highlighting that, in the end, the two structures can work together. This joint work of centralized data structures is known as a Data Hub.
Data Lakehouse
This is a more recent term that arose from the need to combine the benefits of data lakes (large repositories of raw data in their original form) and data warehouses (organized sets of structured data).
Many companies should have several mechanisms to capture data from data lakes and transport it to the data warehouse, in addition to adding mechanisms to control data quality and consistency between repositories. This generates complexity and costs, hence the need to concentrate both solutions in a single repository.
The benefits of this centralization and combination of repositories are diverse: simplified architecture, better data quality, lower costs, better data governance, reduced data duplication, and high scalability.
Despite its benefits, this structure has only recently been applied by organizations, therefore, good practices and techniques are still being formulated and explored by organizations. This is one of the main challenges.
Big Data
When we discuss the significance of storage and the presence of a large amount of data, another relevant term emerges: Big Data.
But what is Big Data? The fundamental difference between the terms Data and Big Data lies in the volume of data. Working with a large volume of data requires computational effort to load and process it, necessitating technological and engineering solutions. The complexity of loading 1 MB (1,000,000 bytes) of data is vastly different from loading 1 PB (1,000,000,000,000,000 bytes). An estimate suggests that the volume of new digital information created should reach 175 zettabytes (ZB) by 2025, according to the International Data Corporation (IDC).
When we discuss analysis or building a predictive model, the longer our track record, the easier it is to ascend the DIKW pyramid. After all, we cannot extract knowledge with a certain level of accuracy and reliability from a small amount of data. Research with 1000 participants will yield more assertive conclusions than research with 10, for example.
Today, there are various approaches to Big Data challenges, but we have chosen the 5 V's that generally encapsulate the challenge of handling large volumes of data.
- Volume: Refers to the size of the data, measured in terabytes, petabytes (or more).
- Variety: The different types of existing data, including structured, unstructured, and semi-structured.
- Velocity (speed): The speed at which this volume and variety of data can be loaded and processed. This is one of the main challenges of BIG DATA.
- Veracity: With the existence of gigantic systems and various data collection sources, the issue of data truthfulness and falseness has become very common, such as combating fake news in the context of Big Data.
- Value: This concerns whether that large volume of information will actually contribute to extracting value for the business. There is no point in having a lot of information if it is of no use in analytical work.
Relevant Data Terms
To conclude our discussion, we will comment on some terms that are very common to hear within organizations.
Data Strategy and Data Governance
Data Strategy is an extremely important aspect of any organization nowadays. It involves all policies, guidelines, and regulations regarding capturing, storing, and working with data.
This term is relevant because it helps to unify how to deal with data across all departments of the company. Although there are structures that integrate data from departments, such as Data Warehouse and Data Lake, we have Data Silos that are limited to each department. It is essential that these data silos receive the same treatment across all departments and that all departments understand their importance. After all, they are the basis for integrated structures. If the marketing department does not understand the importance of data, we will have many difficulties in collecting, storing, and using data related to the marketing department. I reinforce that Data Strategy is not just limited to departments as a whole, it extends to other structures in the data area.
The three elements of Data Strategy are:
- Collection and Capture: How will we collect the data? What data will we generate? What data will be useful for the future? Is there a dataset we can purchase/acquire?
- Clean and Prepare (Curate): How will we deal with inconsistent, duplicated, lost, or invalid data? What tools will we use? How can we validate these decisions?
- Leverage and Capitalize (Consume): How can we generate value from data? Who will access our data (internally or externally)? Will we sell our data? How will we use this data? How to protect our data?
The answers to these questions raise rules and regulations that we call Data Governance.
Governance is this set of rules that must be followed and respected not only by employees but by customers and partners. We cannot fail to mention the existing regulations in relation to data protection, such as the General Personal Data Protection Law (LGPD), which also includes this part of governance.
To understand the difference between these two terms, we can imagine that Data Strategy would be like “We are going to store this data to build a product that performs predictive modeling…” and Data Governance would be precisely the rules, regulations, and policies to make this happen, being something more formal and technical.
Data Culture and Data Driven
Throughout this article, we have seen how important and fundamental data is, as well as how complex it is to consider the structure of data storage and processing. Another complexity for the data area is ensuring everyone in the organization understands its importance and values this complexity. For the data area to become efficient in an organization, it is essential that everyone is aligned with this, not just employees in the area or executives of the organization. If this alignment is missing, it will be very complicated to apply a data strategy and governance, as well as execute the data collection, capture, and storage processes.
Consider a call center company. If the telemarketing attendant does not see the importance of the data, all their calls will be poorly recorded or will lack accuracy. Similarly, if the manager of this attendant does not see the importance of collecting data, they will not enforce and monitor this with their telemarketing operators. Therefore, useful data that could be used in analysis or modeling is lost. That's why it's important for the organization as a whole to have a very clear data strategy.
Here we arrive at the concept of Data Culture, which is precisely understanding the relevance and possibilities that data can generate for the organization and how each person fits within this process. Data culture also involves understanding how to access data, knowledge of existing tools, and having knowledge management so that this area is not just limited to data professionals (how can a marketing professional use data?). It is closely linked to a culture of exploration and experimentation. And of course, these more cultural aspects always require a lot of effort and time to be achieved. It is a construction that always needs to be carried out and encouraged by the organization.
By achieving a data culture, and having and applying a data strategy that reaches all parts of the organization, we can say that the institution is moving towards Data Driven.
Data-driven is an adjective that qualifies data-driven processes, that is, based on the collection and analysis of information. In the business world, it means putting data at the center of decision-making and strategic planning, and seeking reliable sources instead of managing the company by intuition. A data-driven organization is an organization completely guided by data.
Data Platform
To implement the data strategy and assist with the aspects discussed throughout this article, it's essential for the organization to use a data platform. Data platforms enhance data security, improve governance (by recording access, assisting in rule application, etc.), aid in generating visualizations (like dashboards and KPIs), and provide APIs for easier data access. Moreover, these platforms can offer data storage structures, such as Data Lake. Currently, various data platforms are available from different companies, including Amazon and Google.
References
https://medium.com/data-hackers/dados-um-briefing-executivo-ee9297325157
https://cloud.google.com/discover/what-is-a-data-lakehouse?hl=pt-br#:~:text=Um data lakehouse é uma arquitetura de dados moderna que,conjuntos organizados de dados estruturados




