
What is Elasticsearch, how does it work, and why is it so effective? Elasticsearch is simple to configure, has incredible flexibility, and is an excellent tool for complex searches. Let's take a closer look.
What is Elasticsearch?
Elasticsearch is an open-source search engine based on the Lucene library. It was developed in Java and is designed to operate in real time. It can search and index document files in diverse formats. It was designed to be used in distributed environments by providing flexibility and scalability. Now, Elasticsearch is a widely popular enterprise search engine.
Elasticsearch supports a large amount of data without losing performance. It can be deployed on any system, regardless of platform, by providing a REST API. It solves many problems by offering very complex search possibilities, including phonetic search, full-text search, multiple search and parallelism.
How Does It Work?
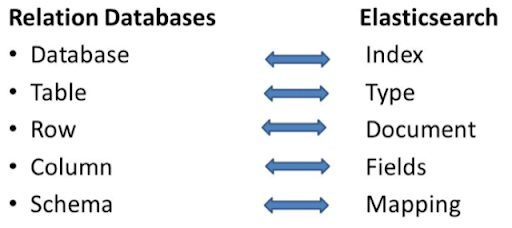
To help understand how Elasticsearch handles data, we can make an analogy to a database.
Elasticsearch stores the data using the "schema-less" concept. This means that it is not necessary to define the structure of the data that will be entered in advance, as happens with relational databases known in the market: Oracle, MySQL, and SQLServer, among others.
In our analogy of traditional relational databases, the structure of the data used by Elasticsearch would be:
- Indexes: The index is a collection of documents that have similar characteristics
- Type: A type in Elasticsearch represents a class of similar documents. A type consists of a name—such as user or blog post—and a mapping.
- Documents: A document in Lucene consists of a simple list of field-value pairs. A field must have at least one value, but any field can contain multiple values.
- Fields: Are columns in Elasticsearch.
In talking about the infrastructure that Elasticsearch provides, we have some important terms to learn.
- Cluster: A cluster is a collection of one or more servers that together hold entire data and give federated indexing and search capabilities across all servers. For relational databases, the node is DB Instance. There can be N nodes with the same cluster name.
- Node: A node is a single server that holds some data and participates in the cluster’s indexing and querying. A node can be configured to join a specific cluster by the particular cluster name. A single cluster can have as many nodes as we want. A node is simply one Elasticsearch instance.
- Shard: A shard is a subset of documents of an index. An index can be divided into many shards.
- Replica Shard: The main purpose of replicas is for failover: if the node holding a primary shard dies, a replica is promoted to the role of primary; replica shard is the copy of primary shard and serves to prevent data loss in case of hardware failure.
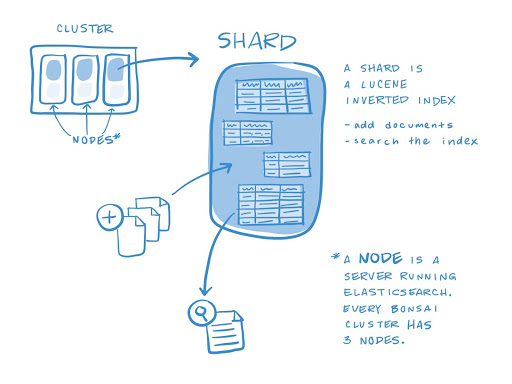
Image courtesy of bonsai
With this structure, Elasticsearch offers us a good API. In addition to the data manipulation API being responsible for replication, it will also take care of the success of transactions, cluster health, and other management jobs.
Here are the main APIs and their functions:
- Cluster API: Operates at the cluster level, such as obtaining statuses from nodes.
- Index API: Responsible for manipulating indexes, such as saving versioned data.
- Get API: Used to retrieve the document, using method HTTP GET.
- Bulk API: Performs operations for multiple indexes and data in a single request.
The "default" configuration of the tool is very robust and scales horizontally. But if a change is needed, it's usually quite simple: this can be done by changing the properties of the application configuration file or through API REST calls.
Why Does Elasticsearch Perform So Well?
First, because Elasticsearch was built to make it easier to manage your activities in a simple and efficient way, as we have already explained, thus enabling you to scale infrastructure as needed.
Second, internally, it keeps the data cached to make the result even more performative. Queries are made when the HTTP GET verb passes the desired parameters.
Third, its storage structure records information in a different way than traditional relational databases; it uses a structure we call an inverted index. In this case, the index is the same as in the relational database, i.e. a structure already known, which helps to store data for future use.
For example, imagine that we want to search all articles that contain the word "Brazil" in the title or text. How would we do this in a relational database?
We would have to use a query like this:
SELECT * FROM article WHERE title LIKE '%Brasil%' OR text LIKE '%Brasil%';
In this case, we know that using indexes in the columns will not be a good option, especially in the "text" column, because we need to use the operator "LIKE" involving the search on the wildcard "%", which introduces a big performance issue.
The query won't be effective at all since the database will have to go through all the records to find the words within the columns, so it will make a fullscan in the table, and this will not be good. Imagine that this table has millions of records...
It is at this time that our friend inverted index stands out. Its structure is assembled through the words, which are called "terms" in Elasticsearch. #CodingExplained offers an excellent introduction on the inverted index:
"The purpose of an inverted index, is to store text in a structure that allows for very efficient and fast full-text searches. When performing full-text searches, we are actually querying an inverted index and not the JSON documents that we defined when indexing the documents...
An inverted index consists of all of the unique terms that appear in any document covered by the index. For each term, the list of documents in which the term appears, is stored. So essentially an inverted index is a mapping between terms and which documents contain those terms. Since an inverted index works at the document field level and stores the terms for a given field, it doesn’t need to deal with different fields." - #CodingExplained
Alright, so let’s look at an example. Suppose that we have two recipes with the following titles: “The Best Pasta Recipe with Pesto” and “Delicious Pasta Carbonara Recipe.” The following table shows what the inverted index would look like.
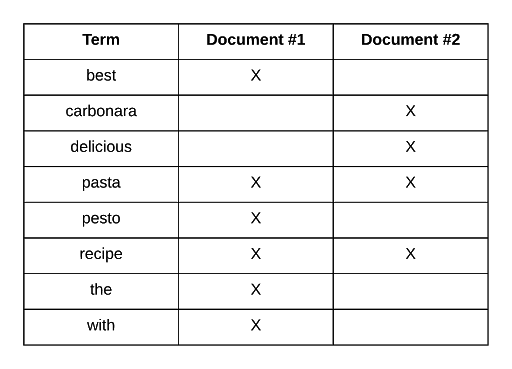
So the terms from both of the titles have been added to the index. For each term, we can see which document contains which term, and this enables Elasticsearch to efficiently match documents containing specific terms.
The first step of a search query is to find the documents that match the query in the first place. So if we were to search for “pasta recipe,” we would see that both documents contain both terms.
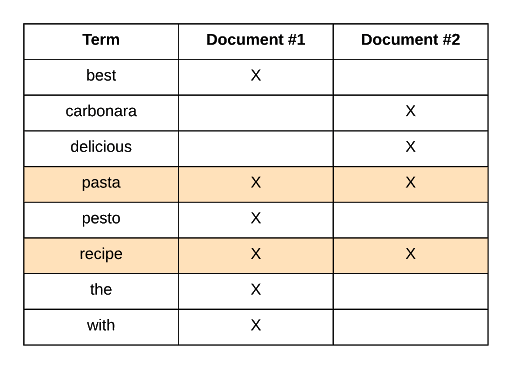
If we searched for “delicious recipe,” the results would be as follows: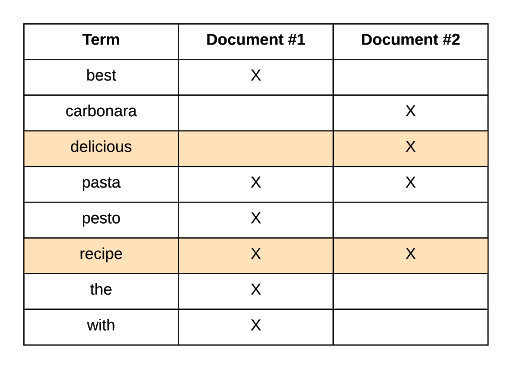
As we can see, an inverted index structure contains the following information:
- Term: the term itself.
- Frequency: the number of times the term appears in this field, in the sum of all documents.
- Documents: which documents have the term.
Elasticsearch applies some rules to save each word separately and simply for future searches. It's what we call the analyze process.
Now you can see why Elasticsearch is so fast for searches: it already has the term saved and knows which documents have it, so you don't need to fullscan the data.
Of course, Elasticsearch has an effective implementation to work with data in memory and manipulate the data in the operating system, but the fact that it uses inverted indexes definitely makes it more appropriate than relational databases when it comes to searches.
Elasticsearch will "break" a text into terms so that it can create this index. To separate words from the text, it uses a technique called analyzer. This technique is responsible for processing the text being saved. The default analyzer is called "Standard Analyzer."
Generally speaking, what the analyzer does is:
- Supports removing stop words;
- Separates the words (usually by a space);
- Leaves the words in lowercase;
- Removes punctuation;
- Removes articles;
With this, Elasticsearch can store words in a very uniform way. Here's what the following text would look like: "Is this dèja vu?"
The terms would look like this: [ is, this, deja, vu ]
Note that the procedure separated the words and applied the quoted rules before saving the term.
These are some of the main procedures performed by analyzers. There are several types of analyzers, and each has its own set of rules to apply to the data. You can also create your own analyzer using an existing set of rules or even creating your own rules.
In addition to these techniques, Elasticsearch has several settings to give weight to a certain field, such as frequency of the term, the length of the term, frequency of the reverse document, etc. to retrieve documents with accuracy and speed.
Conclusion
Elasticsearch can be a great way to optimize your product, improving the search by making it faster and enabling more complex searches. It's a simple tool to configure, has incredible flexibility, and is an excellent option for data searches and complex searches.
It has the power to execute queries quickly and with excellent results. Elasticsearch provides excellent documentation, and its ever-growing community is active and helpful.



