
Today, we'll discuss the ways in which ETL tools can connect, consolidate, and sync data between OLTP and OLAP systems. We'll begin by defining the uses of OLTP and OLAP systems and then explore how ETL tools can connect them.
First, let's define the uses of OLTP and OLAP systems. There are essentially two kinds of database design: One is used to accomplish the requirements of an end-user application and the other to provide modeled records for data engineers. The former is designed for OLTP (Online Transactional Processing) systems and is used to persist operational data; it is characterized by a high-normalized schema, lots of tables, and a large volume of short, online transactions (INSERT, UPDATE, DELETE). The latter is designed for OLAP (Online Analytical Processing) systems and is used to persist consolidated data from foreign operational sources; it is characterized by a de-normalized schema with fewer tables (mostly using the star model for multi-dimensional expression queries), a small volume of transactions, and higher performance so that it can run complex queries over a huge volume of data — including historical records from past loads.
 source: www.rainmakerworks.com
source: www.rainmakerworks.comAlthough OLTP databases are the foundation for any end-user application, they are not the perfect source for most of the queries required in the data mining processes. Their common-normalized schema, required to avoid redundancies ( which could lead to data inconsistencies or the need for time-consuming transactions ) makes queries too complex and expensive, due to the many required table joins and subqueries.
On the other hand, databases designed for OLAP systems do not need to account for data changes and related consistency issues. This allows for a de-normalized schema structure with fewer relationships. Also, since they commonly serve solely to analyze data and do not deal with application state repositories, time-consuming queries may be performed as part of the process when needed.
OLAP systems require a special kind of schema that allows client tools to run multi-dimensional queries. This schema, commonly called star schema, is characterized by a main table, called a fact table, which stores dimensions (e.g. date, location, etc.) as foreign keys from various reference tables. It allows the system to handle the data as hypercubes, which could be sliced and diced, drilled down, rolled up, and pivoted. All these operations are the core from which data engineers can make sense of meaningless/raw data.
With the advent and evolution of data mining processes and algorithms, OLAP database systems have became more necessary. Data, however, must still come from operational sources, which have been and always will be constrained by performance and consistency optimality. To allow both these worlds (OLTP and OLAP systems) to coexist, we need a process to connect them and keep them synced. This is where ETLs come in.
The ETL (Extract , Transform , Load) is the main process that allows engineers to manage data for business intelligence and data mining analysis. It uses available operational databases as sources for a consolidated and well-modeled container that can handle required queries and experiments while avoiding side effects for application users.
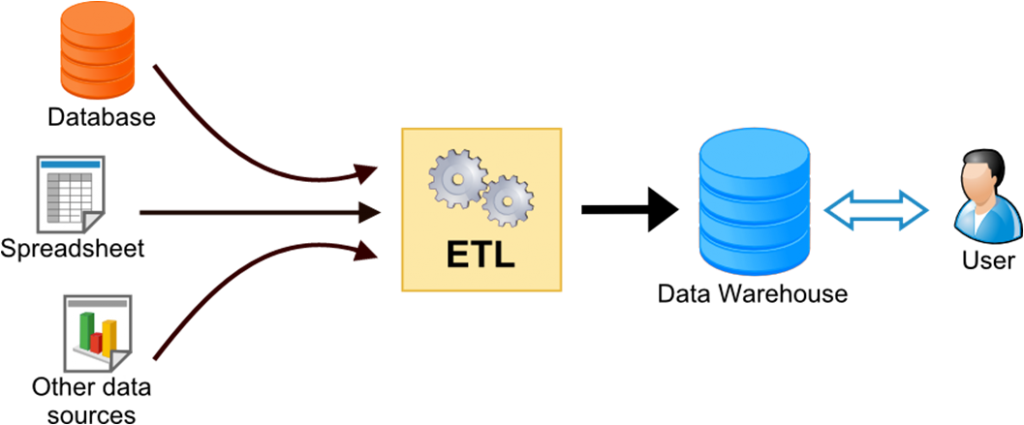
The Data Warehouse is the consolidated database, created by the ETL process, from one or more sources of data. Data Marts, which are small databases with a subject-focused dataset from the main DW, are important components of this architecture.
One feature that any architect must consider when selecting an ETL tool is its capacity to extract and load information from different types of data sources. This reduces the need for other integration systems in the analytical layer (and also for intermediate ETL flows ), which is easier to maintain and extend when a new source of data becomes available.
In the majority of cases, the need for an ETL appears not during design but rather during the lifecycle of an application. Even when using new database architectures, like document and graph databases , which can have a hybrid model for both transactional and analytical processes, the ETL can be a valuable tool to consolidate other sources for a broader analysis. In these cases, there's a common need to sync the operational database with another to free more time and computer resource consumption, which ETLs can also do.
Although ETL tools are more common in the enterprise environment, there are plenty of solutions available for low-profile companies. One of the best is the scriptella project. As a JVM-based project, it uses JDBC as its connection framework and an embedded script engine for the transform/load phases.
For a more complete solution, there are the Pentaho tools. Besides offering a GUI ETL tool, Pentaho allows the architect to count with a BI platform. It also has a report designer tool as well as an OLAP database (Mondrian) that provides an analytical interface to the operational database through an in-memory, multi-dimensional schema.
Many more tools are detailed in the awesome-etl project, which offers a list sorted by programming languages, including some other GUI-based tools.
Conclusion
ETL tools, then, are useful for connecting OLTP and OLAP systems while consolidating and syncing data. In some scenarios, you can only use your database's replication feature to make processes work. That is, an engineer has to make long and complex queries to create a continuous, synced instace of your data without affecting the application's usability. In other scenarios, you can use the same database as the application when its design is appropriate for the job. The best rule of thumb is: evaluate the effort to manage an ETL — and a data warehouse — and when it doesn't make sense, keep things simple. It's important, however, to recognize the solutions ETLs provide so that you can make smart decisions when application requirements start creating new problems.
Happy coding!




