
File-sharing is one of the most elementary ways to perform system integration. In the context of Web applications, we refer to the process where a user sends data/files from a local computer to a remote computer as upload.
Sometimes we need to expose an upload operation in our REST API that allows us to transmit:
- -Binary files of any kind
- -The meta information related to it
- -Any additional information needed to perform business logic processing
The catch is, we want all this information to arrive to the server in the same request. Sounds like a challenge, doesn't it?
The purpose of this article is to demonstrate a strategy, among several existing ones, that allows us to implement this integration scenario using resources provided by the Mule components.
SOAP Legacy - Identifying Reusable Concepts
To provide some context, this strategy was inspired by the architecture of a legacy project that I needed to maintain. It was aimed at helping to execute the transmission of binary files in SOAP Web Services without the use of MTOM.
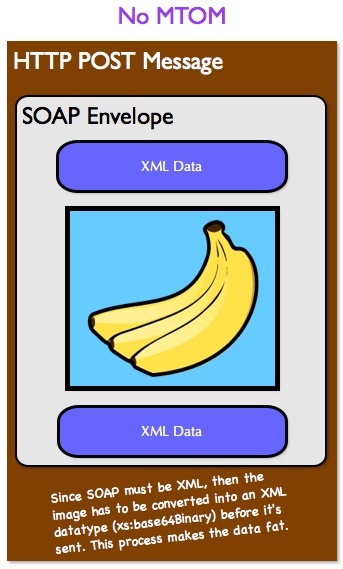
When we don't intend to use MTOM with SOAP, where the files are transmitted as MIME attachments of the payload, the implementations of the protocol convert the contents of the file to be transmitted and the result of this conversion is a binary string in the Base64 format.
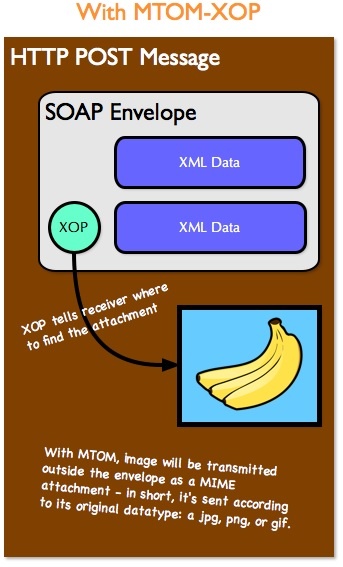
After the conversion, the String is deposited inside an XML tag, which is a part of the Body content of the payload being transmitted to the remote server as shown below.
The advantage of using this strategy is that we're now able to transmit this tag in the same payload which may contain other information, such as the data needed to process business rules, or better yet, the meta information of the file. Since all the necessary information is in the same payload, the process of reading and/or parsing the message is largely simplified. This is all handled by the service in a single request, which is very important for the processing economy and feature maximization. It means we don't have to worry about the maintenance and/or management of transactions handled by the service. We have achieved Stateless behavior.
This is very desirable because it conforms to one of the great features of the HTTP protocol (which was designed to be Stateless) and allows the transaction to be completely processed in one request. Therefore, it won't be necessary to request additional information for the service consumer, plus, we can still have part of the treatment process done internally and asynchronously without prolonging the client response time. Finally, since there's no need to request additional information regarding the transaction in progress, it provides server resource savings as there will be no need for further processing.
Implementation - Porting The Solution to REST API
When making use of any interface, we should consider the fact that consumers usually expect to find availability, simplicity, and stability. Defining a RAML contract is one of the ways that we can establish guidelines that favor the construction of a REST API that intends to offer simplicity and stability. Just as we do with WSDLs, when we define and make a RAML available, we give our consumer a better chance to prepare for it as well as identify difficulties and provide suggestions for improvements for future versions of the contract.
Using ready-made infrastructures, such as the Mulesoft API Design cloud platform, the consumer can also test this RAML by generating an endpoint with mock information provided in the RAML itself, allowing the consumer to test the interface in its consuming part.
In order to implement the proposed scenario above, we need to define the RAML contract containing the POST operation for the resource "file" like so:

For a resource like this, we can have the following HTTP request example:

Below, I explain the different flows that make up the Mule project of the REST API, which is running as Runtime Mule Server 3.8.1 EE.
Main Flow:
It consists of an HTTP inbound endpoint configured to handle requests on port 8081, an APIkit Router, and a Reference Exception Strategy.

Post Flow:
The APIkit Route sends HTTP Post requests to this stream. It consists of two triggers (Flow References) for the buildFileData stream and filesSplitter, a DataWeave to prepare the response that is returned to the consumer, and a Logger.

Build FilesData Flow:
This flow declares both the FilesContent variables (a java HashMap) and FilesData (a simple String var). In this flow, you can find a ForEach that traverses the inboundAttachment of the current message (a multipart-formData) to separate the FileContent [] from the filesData. There's also a component that can be used to remove the rootMessage variable generated during the interaction of the ForEach. Lastly, there is the DataWeave that performs the merge of the original FilesData Payload with the FilesContent data. This is done to simplify the activity of passing binary data within a JSON for the consumer.

Files Splitter Flow:
This flow converts the received JSON FilesData into a built-in Mule Java object. This object is partitioned with each part representing a file that will be sent to the outbound VM component where each file is processed separately. The Collection Aggregator component is responsible for gathering the enriched payloads in the same structure.

Upload File Flow:
As suggested by the documentation, we can use an inbound VM to handle requests originating from a Message Splitter. Within this flow, each file is preprocessed to be sent to Amazon S3 by the Create Object operation. The pre-process consists of converting the Base64 binary String from the "fileContent" field of the payload into a BiteArray. The result of this conversion (here performed by the base64-decoder component) is stored in a variable.
The Create Object component is then satisfied with this variable along with the file and bucket names. Because this operation doesn't give a usable response back, we add a call to the Get Object component that allows us to retrieve data from the file that was in storage.
Lastly, with the help of a DW, the data received at the beginning of this flow is enriched with the FileSize and HttpURI data that was received in the response of the S3 Get Object operation.

Exception Mapping Flow:
Mule automatically generates this flow when we create a project, providing some RAML file to the APIKit. It offers some exception treatments handled automatically by APIKit.

Testing the Solution
Most simple REST API tests, especially those involving GET operations, can easily be done by command line utilities such as cURL. Stress tests can be generated with the help of the JMeter tool as well. Tests can also be performed on newer versions of SoapUI. I opted to perform the tests with the help of the Postman tool (an extension for the Google Chrome browser).
We can submit more than one fileContent[] as form param, but only the indexes reported as being used in the JSON passed in the form param "filesData" will be processed by the API. All others will be ignored.
If no exceptions occur, we will then receive a JSON containing the processed data and HTTP status 201.


Conclusion
And that's it folks. I want to hear your thoughts on this tutorial and any other techniques you would like to discuss or share. Please comment below!
References
https://stackoverflow.com/a/15572342
https://docs.mulesoft.com/mule-user-guide/v/3.8/amazon-s3-connector
https://www.tutorialspoint.com/jmeter/
https://curl.haxx.se/docs/httpscripting.html
https://www.soapui.org/rest-testing/getting-started.html
https://objectpartners.com/2016/07/12/working-with-the-postman-rest-client/





