
In this post, I will go over a real example of how developers can use Reactive Streams to build more responsive Microservices. I will also conduct a progressive analysis on the steps that need to be taken in order to make the change from an application using Spring MVC to one using Spring WebFlux and RxJava, as well as how to apply reactive programming and work with streams of data.
Reactive Streams
“Reactive Streams is an initiative to provide a standard for asynchronous stream processing with non-blocking back pressure.”
reactivestreams.org1
While most developers are familiar with the concept of stream processing, the understanding of back pressure is essential to Reactive Streams. When developing message driven systems, it is common to use a "push" relation between consumer and producer. The producer sends messages to the consumer as soon as they are available, and if the consumer is not able to process these messages in real time, they are stored in a buffer. One point of concern with these types of systems is dealing with the excess amount of messages in the buffer when the producer is faster than the consumer. In real systems, neglecting this scenario often leads to slow response times for clients, excessive resource consumption, and even downtimes. Back Pressure solves this problem by using a 'pull' relation between the producer and consumer. Now, the consumer informs the producer on how much data it can process, and the producer only sends the amount of data requested by the consumer. Reactive Streams provides a standard interface for this relationship between consumers and producers of data. In Java 9, Reactive Streams is accessible through a set of interfaces in the class Flow2 at the package java.util.concurrent.

Interfaces
Publisher: A Publisher is the producer the of data, according to the demand requested by its Subscribers.
Subscriber: The consumer of the data produced by a Publisher.
Subscription: A Subscription is the result of a Subscriber subscribing to a Publisher. It is the means that a Subscriber can utilize to request more data.
Processor: Represents a processing stage, being both a Subscriber and a Publisher.
How It Works
When an instance of Subscriber is passed on to a Publisher, it will receive a call on its method, onSubscribe(Subscription), but it will not start receiving any events yet. Items will only be received by the Subscriber when it calls the method request(long) in its Subscription, signaling a demand for new items. The Subscriber can receive data through three distinct methods:
- Subscriber.onNext() is invoked with the next item and can be called n times, with n being the long value passed on the method request(long) of its Subscription.
- Subscriber.onError() is invoked when an error occurred while processing the stream.
- Subscriber.onComplete() is invoked when there is no further data to be processed.
In the case of onError() and onComplete(), no new data will be emitted, even if the method request(long) is called again.
Developers can implement these interfaces directly into their projects but should be aware that the implementation of back pressure in asynchronous systems is a complex task3. Instead, they should use some of the available implementations of Reactive Streams like RxJava4, Reactor5, and Akka Streams6. The examples in this article were created using RxJava.
RxJava
RxJava is one of the implementations of the Reactive Streams API in the JVM. It is a very lightweight library composed of a comprehensive set of operators, allowing the manipulation and composition of streams using a fluent API. RxJava also implements the Reactive Extensions7 API, an interface for asynchronous programming using the Observable Streams pattern available in many different languages.
Spring WebFlux
Spring WebFlux8 is a framework that provides better support for reactive programming for the Spring Framework 5, offering developers the ability to create servers and clients that support HTTP and WebSockets using a reactive stack.
The Microservice
The Microservice is part of an e-commerce platform. All the information concerning the products sold online is stored in a Cassandra9 Cluster. Cassandra is a distributed NoSQL database, generally used when scalability, high availability, and performance are needed when working with large amounts of data. The task of the Microservice is to receive a HTTP GET request with a list of product identifiers in the format of UUIDs, and return all product information to each corresponding UUID stored in Cassandra. During the development of the Microservice, changes will be made in order to make it more responsive, reducing the time it takes for the list of products to be made available to the client.
Using Spring MVC
Using SpringMVC, the code is pretty simple. First, the domain class Product is defined:
Product.java:
The Product class is a simple POJO representing the products stored in Cassandra. The annotation @Table maps this class to a table called products. The @PrimaryKey annotation indicates that Cassandra stored the attribute id as a column named product_id used as the primary key of the table products.
ProductRepository.java:
The interface ProductRepository extends the interface CassandraRepository10 from the module Spring Data Cassandra11. This interface already has commonly used methods to access data in a Cassandra database like count( ), findAll( ) and findOneById( UUID ).
ProductService.java:
The class ProductService just calls the method findAllById( List<UUID>) from the bean productRepository and returns to the List of Products found in the database.
ProductController.java:
The ProductController exposes the HTTP GET endpoint that receives the list of UUIDs as a web request parameter, and returns a List of Products in the body of the HTTP response in the JSON format. The image below shows a simplified timeline of the application when a request is received:

Using Spring WebFlux
Now, the Microservice will be updated to use Spring WebFlux instead of Spring MVC. After adding the dependencies in the classpath, the first change needed is in the class ProductService:
ProductService.java:
ProductService now returns a Publisher12, from the Reactive Streams API, instead of a List of Products. Flowable is the class in RxJava that implements the Publisher interface. The method Flowable.fromIterable(Iterable) from RxJava creates a Flowable from a class that extends Iterable, in this case, a List. This method call will create a stream that will emit all the Iterable items to its Subscribers. RxJava offers a broad range of utility methods to create streams from other classes like Array, Future, and Callable.
ProductController.java:
Spring WebFlux allows the ProductController to return a Publisher and handles the subscription to the returned stream.
Divide And Conquer
The Microservice is now using a reactive stack, but some improvements can be made to reduce the application response time. Cassandra is unique in that queries using the IN clause with a set of keys tend to perform poorly when compared to the use of separate queries by individual keys13. When using the IN clause, the node that receives the query will be responsible for coordinating alongside all the nodes that have data related to the query before returning the result to the application. Querying for the keys individually turns out to be more efficient, especially if using a TokenAware14 Java client that already knows which node contains the data by the primary key.
A code change is necessary to reflect this optimization:
ProductService.java:
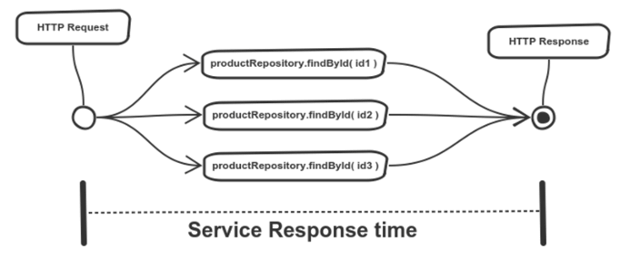
The method findById(UUID) from the interface ProductRepository returns an Optional, a container for values that may or may not be null. The Flowable.fromIterable(Iterable) method is still used to create the stream, but now with the UUIDs provided as a request parameter as the source. From now on, RxJava fluent API can be used to apply modifications to the stream and manipulate the data. The first call is to the method map, which transforms the stream. The map function is used to query the database for every UUID in the stream, converting a stream of UUIDs into a stream of Optional<Product>. The method filter will only let items that pass a given condition to propagate further into the stream. Any empty Optional returned from the query is filtered, and the map method is used again to convert a stream of Optional<Product> into a stream of Product objects. The timeline can now be updated to represent what is executed during a request to the Microservice:

Going Parallel
While the Microservice is now more efficient in getting the data from Cassandra, there is still room for improvement. The service makes the queries to the database in a sequential manner, but what if it executes the queries simultaneously instead? Considering a database that is under a normal load, the response time can be further reduced. That is where the concept of processing asynchronous data comes into play, using the RxJava API to make the requests to the database in parallel and coordinate the retrieval of data for the client. For every UUID, the Microservice will make an asynchronous query to the database, and when the queries are completed, merge their results and send the response to the client.
First, another repository is created, called ProductAsyncRepository:
ProductAsyncRepository.java:
The productRepository will now use AsyncCassandraTemplate, a utility class from Spring to assist in the creation of asynchronous queries for Cassandra. The method findOneById( UUID ) returns a ListenableFuture, a class from Spring that extends java.concurrent.Future, a representation of an asynchronous computation. This change allows us to make the query to the database without blocking the main thread. To retrieve the result later, a call must be made to the Future.get() method, which will return the List of Products that matched the query.
Next, the class ProductService is modified:
ProductService.java:
Flowable.fromIterable( List<UUID> ) still creates a list of UUIDs, but now the stream uses the operator flatMap instead of map. flatMap() receives a function that has the current stream item as an input and returns as a stream. The emissions of the streams returned are then merged and returned as a new stream.
The stream is created with the method Flowable.fromFuture(productAsyncRepository.findOneById(id), Schedulers.io()). The first parameter is the result of the recently created repository method, and the second parameter is a Scheduler, which is a utility class that abstracts concurrency in RxJava. By passing Schedulers.io() to the method, RxJava will then free the current thread and use a thread pool designed especially from IO-bound work to wait for the Future to be completed. The last operator in the stream is another flatMap, which converts the arrays of the streams in a stream of its items. Now, the timeline can be updated to match the changes made to the application:
Conclusion
Throughout the process, it was possible to identify the changes in the code and behavior of the Microservice. The use of Reactive Stream increased the service responsiveness keeping the code readable. Although this was a simple example that only had a few RxJava operators and no error handling or back pressure, it gives a good idea of the ways one can use Reactive Streams in a Microservice. The final section will address FAQs that developers usually have about the subject.
Can’t I Do This With Core Java?
This is by far the most commonly asked question. The answer is always the same: of course, you can! A solution using only core Java would be easier to digest for someone without a background in functional programming. The only dependency of RxJava is the reactive-streams API since it implements everything using only core Java. Experience tells us that developing responsive applications is not always as simple as the example above. It is unlikely that responsiveness is your application’s only need. Scalability and high availability are also necessary. Usually, there is more than one query in the database as well as many requests to other services. When taking those factors into account, the application will need to use thread pools, Executors, and Future objects. The blend of all these technologies in big projects tends to create messy and disorganized code. This causes you to neglect performance; instead, you’re pre-occupied with worry over whether the next commit will break the system. Tests are much more difficult to implement now because you have so many variables that tuning your application has more to do with instinct than with logic. With the use of reactive-streams and RxJava, you get an implementation of Reactive Streams with many compositional patterns, testing utilities, and an open source community to help you achieve responsiveness, resilience, and scalability throughout all layers of your Microservice.
Why RxJava And Not X ?
That is typically matter of personal choice as well as an analysis of the requirements of the product you are trying to build and how comfortable your team is with the technology. The fact that Reactive Extensions are available in many different languages and that the Java version is very lightweight and can be used alongside other frameworks are points to consider. However, Reactor and Akka Streams are also great tools. Therefore, it is recommended that you experiment with both of them to see which one you are most comfortable using.
The Downsides?
The RxJava learning curve can be a little steep, especially if you do not have a background in functional programming and knowledge of functional operators. Debugging is more complicated because now you have RxJava operators wrapping your method calls, and you are using method references and lambdas. You will struggle with your IDE a bit in the beginning until you can determine the parameters and the return type of your streams. Like every technology, RxJava and Reactive Streams are not always the best tools to use to solve every problem. They are an elegant way to work with asynchronous streams of data, but you should definitely analyze your system requirements to determine whether it is a good fit for your problem.
Citations
1http://www.reactive-streams.org
2http://download.java.net/java/jdk9/docs/api/java/util/concurrent/Flow.html
3https://github.com/ReactiveX/RxJava/wiki/Implementing-custom-operators-(draft)
4https://github.com/ReactiveX/RxJava
5https://projectreactor.io
6http://doc.akka.io/docs/akka/current/java/stream/
7http://reactivex.io
8https://docs.spring.io/spring-framework/docs/5.0.0.BUILD-SNAPSHOT/spring-framework-reference/html/web-reactive.html
9http://cassandra.apache.org
10https://docs.spring.io/springdata/cassandra/docs/current/api/org/springframework/data/cassandra/repository/CassandraRepository.html
11https://projects.spring.io/spring-data-cassandra/
12This example uses Java 8, so the Publisher is the one available in https://github.com/reactive-streams/reactive-streams-jvm/tree/v1.0.1
13https://www.datastax.com/dev/blog/java-driver-async-queries, Case study: multi-partition query, a.k.a. "client-side SELECT...IN"
14http://docs.datastax.com/en/drivers/java/2.1/com/datastax/driver/core/policies/TokenAwarePolicy.html




