
In microservices-based software architecture, distributed transactions are very common. In these instances, when there are multiple services and databases in play, data integrity may be jeopardized. This is when we need to use the SAGA pattern.
Overview
One of the benefits of microservices architecture is the ability to select different technologies and databases for each service. For example, you might choose to use an SQL database for service A and a NoSQL database for service B. This independence of configurations optimizes the performance of each service.
Once services start to interact with each other, however, a business transaction may cross multiple services, introducing challenges with data consistency and integrity.
The SAGA pattern gives us a way to manage data consistency in distributed transactions. The pattern is a sequence of local transactions that update the services participating in the “saga” to provide transaction management.
Origin
The original concept of SAGA appeared in 1987 when two Princeton University computer scientists, Hector Garcia-Molina and Kenneth Salem, created the concept to support transitions or long operations, called LLTs (Long-Lived Transactions).

Image courtesy of cs.cornell.edu
SAGA Pattern
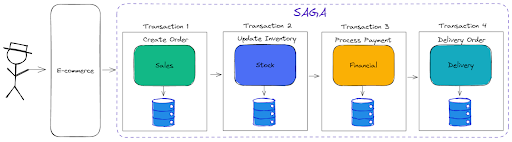
In order to understand how to apply the SAGA pattern, let's imagine a scenario with an e-Commerce application where there is a sequence of actions that need to take place when a consumer places an order. Simply put, this sequence is:
- Register the order.
- Update the inventory.
- Process the payment.
- Deliver the order.
The SAGA pattern helps us manage each phase of the process using a sequence of local transactions. Each local transaction updates its own database and publishes a message that can be a command or an event to trigger the next transaction. At the end of SAGA, all the microservices will have updated their databases so that the data in each is consistent.
Compensating Transactions
If a local transaction fails, the SAGA pattern will execute what we call a compensating transaction that will undo the previous local transaction.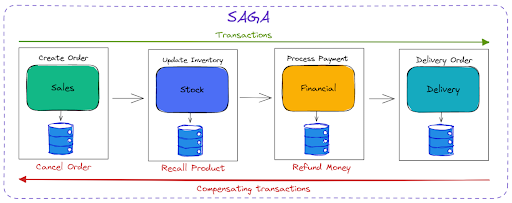
One interesting detail to note is that if an error occurs and the compensating transaction generates a new event or updates the previous state, the order will not be deleted; instead, its status will be updated to "canceled."
So when you use the SAGA pattern, you meet with definitive success or definitive failure.
There are two approaches to implementing the SAGA pattern: choreography and orchestration.
Choreography
In this strategy, each component of the SAGA pattern exchanges information without a centralizing point. Each event needs to inform its successor that it was able to execute the transaction, or else notify its predecessor if the transaction fails.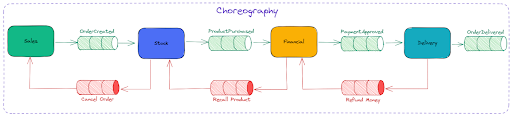
Advantages:
- Good for simple workflows that require few participants and don’t need coordinator logic.
- Doesn’t require additional service implementation.
- Doesn’t introduce a unique point of failure, because the responsibilities are distributed across the SAGA participants.
Disadvantages:
- The workflow can become muddled when adding new steps, because it’s difficult to track which participants of the SAGA listen to which commands.
- There’s a risk of cyclic dependency between the participants of the SAGA because they have to consume each other's commands.
Orchestration
Orchestration is a way to coordinate SAGA from a central controller called the SAGA Execution Coordinator (SEC) or Orchestrator. The SEC is an additional component responsible for controlling the events between the services participating in the SAGA.
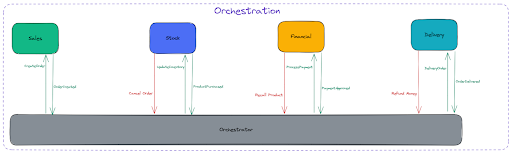
Advantages:
- Good for complex workflows involving many participants or new participants added over time.
- Suitable when you need to control each participant in the process as well as the activity flow.
- Doesn’t introduce cyclic dependencies, because the orchestrator depends unilaterally on the participants of the SAGA.
- SAGA participants don’t need to know about commands issued to other participants. Clear separation of concerns simplifies business logic.
Disadvantages:
- The external design complexity requires the implementation of coordination logic.
- There is an external point of failure since the orchestrator manages the complete workflow.
Considerations
- The SAGA pattern can be challenging in the beginning because it requires a new way of thinking about how to coordinate a transaction and keep the data consistent for a business process that spans multiple microservices.
- The pattern is particularly difficult to debug, and the complexity grows as participants increase.
- Data can’t be reverted because SAGA participants commit changes to their local databases.
- The implementation must be able to handle a set of potential failures and provide idempotence to reduce side effects and ensure data consistency.
- It's best to implement observability to monitor and track the workflow of the SAGA.
- The lack of participant data isolation poses durability challenges. SAGA implementation should include countermeasures to reduce anomalies.
SAGA Example
This SAGA project shows a practical example of how to implement the SAGA pattern using C# with ASP.NET and RabbitMQ and contains essential settings to work with observability using OpenTelemetry. This example can help you visualize the events and calls between the services.
More details on how to execute the services can be found in the README of the repository.
Conclusion
Today we introduced the SAGA pattern and explained its use in microservices architecture, as well as the pros and cons of the two SAGA configuration approaches. Finally, we looked at a practical example of an application developed using the SAGA pattern to orchestrate transactions between services.
Comment if you have any questions or suggestions!
References
"SAGAS" by Hector Garcia-Molina and Kenneth Salem. cs.cornell.edu
"Pattern: Saga" by Chris Richardson. Microservices.io
"Saga distributed transactions pattern" learn.Microsoft.com
"Saga Pattern in Microservices" by baeldung. baeldung.com



