
There's a lot of interest in learning some form of machine learning/predictive analytics or AI these days, but knowing where to start can be difficult. I recommend learning TensorFlow on Colab (along with NumPy and pandas), because TensorFlow has support for developing many standard AI/ML models quickly and Colab gives us a user-friendly online environment for experimenting.
What is TensorFlow?
TensorFlow is an open-source machine learning framework developed by Google. It has support for many machine learning techniques and can be used with other popular Python frameworks to develop machine learning/AI models.
What is Colab?
Colab will be familiar to anyone who has used a Jupyter Notebook to process code. It allows you to write documentation and runnable code within the same document. Colab uses the same technology and is especially useful since there is no setup required. Colab also offers additional features like code snippets, datasets that can help you learn and explore, and the use of servers on Google Cloud, including hardware acceleration with GPU/TPU processors and data storage. You can go to Colab's website and create a new notebook, view an example, or upload one from your Google Drive or GitHub.
Here is an example of getting to the ready-made code snippets to ease your development efforts:
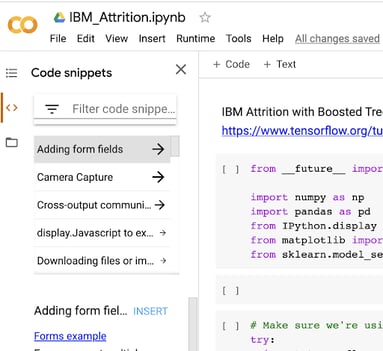
Why Learn Data Science/AI Tools?
Even if you aren't interested in taking a deep dive into AI, there are many reasons why it's useful for any programmer to become acquainted with these tools. The TensorFlow framework can make some basic implementations easy to accomplish. As coders, we already have an essential head start in that we can code and often have enough background in mathematics that will allow us to dive into more sophisticated models.
Data science projects don't just need data scientists. Some industry estimates assume that there is a need for 2-5 data engineers for every data scientist. A large amount of time spent on an analytics project will be in developing systems for collecting and preparing data. Still, your ability to play a part in the exploratory phase of data analysis will be a great benefit to your client.
Implementing a Convolutional Neural Network (CNN) to classify cats and dogs is exciting and something that can be done with a relatively short program. And of course, this type of model could be useful in many types of applications. However, here I will focus on a more typical business-centric analytics problem. There are many use cases for clients, including using Natural Language Processing, to develop models for chat machines or analyzing customer feedback. These can be done using models like Naive Bayes for spam detection and Random forest, an ensemble of decision trees, to be used on tabular data for optimizing marketing campaigns.
Next, I will show you an example of using a BoostedTreesClassifier to inspect employee attrition data. The boosted tree is an ensemble technique that works on familiar decision trees, but it employs machine learning by repeating the process and learning from prior mistakes, adding and removing elements and data for randomness.
Business Case
Employee attrition is a high cost for employers, and taking time to retain talent is time-consuming and expensive. Next, we'll explore an example of the IBM Attrition data set to gain some insights on root causes.
I've placed my notebook on GitHub if you are interested in working with it. You can create your notebook here.
Let's bring in our primary tools: NumPy, pandas, and scikit-learn.

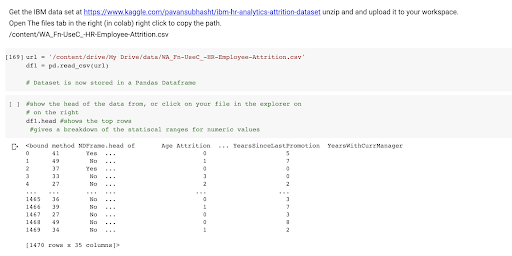
Load the data set. I've given a link to the IBM attrition data set in the code. You can upload it to your Colab work space or retrieve it from Google Drive by connecting your account.
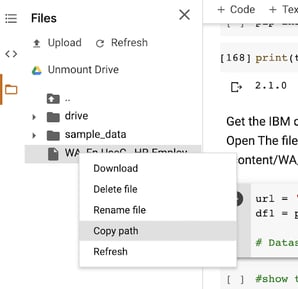
Once you have the recordset, you can open the explorer on the left, then right-click to copy the path:
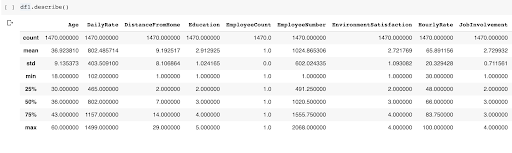
Now that you've loaded your data, take a look either by using the describe() function on the DataFrame object or by clicking on your original data link and opening the data explorer on the right side of the screen:
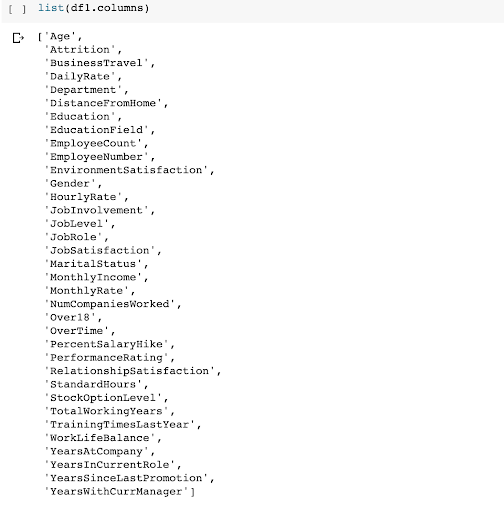
List your columns so that you can copy and paste them into the code later. Our target variable is going to be "Attrition," which will be used against the other fields to build the classifier.
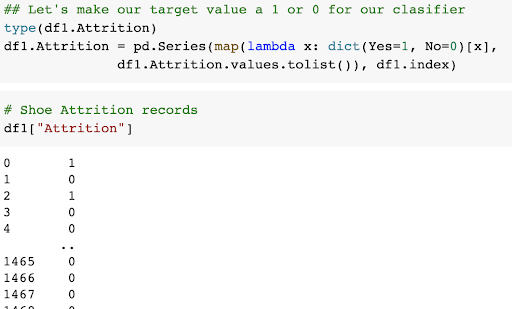
Let's take a look at the "Attrition" records:
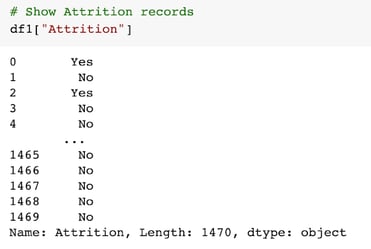
The records are either "Yes" or "No." We'll need to transform this data into a numerical representation:
Split the data set, using 80% for training and 20% for testing.
Notice the number of records for each is from a total of 1470 records with 35 columns:

Take the 'Attrition' value out since we are using it as our target:

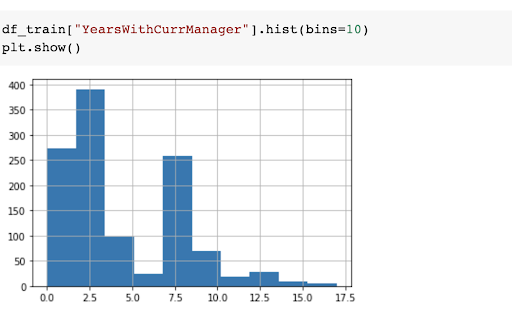
Now take a look at the data. Below is a histogram based on the time an employee has spent with a current manager:
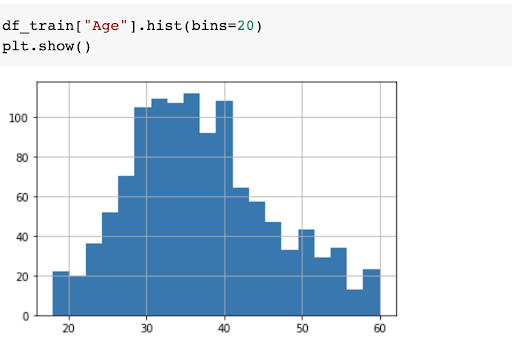
 And here's another histogram-based on age:
And here's another histogram-based on age:
Build the Predictive Model
Okay, that brief inspection was easy. Now let's build the predictive model.
Here we separate the categorical columns from the numeric columns. The goal is to treat categories as numeric values for the model's evaluation. For instance, "Gender" will internally be set: Male=0, Female=1.

Set up your evaluation input functions:

Now we run our BoostedTreesClassifier. With the libraries in our TensorFlow package, we can run other classifier models as well. The estimation accuracy for our first run is almost 87%, and the Area Under the Curve (auc) is over 80%, indicating decent true positive predictability.
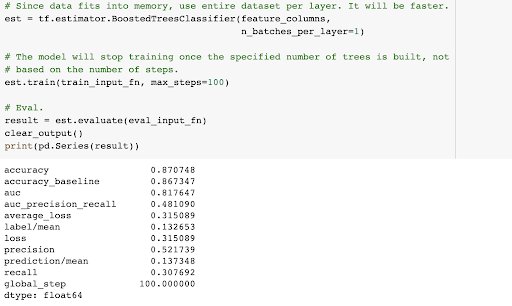
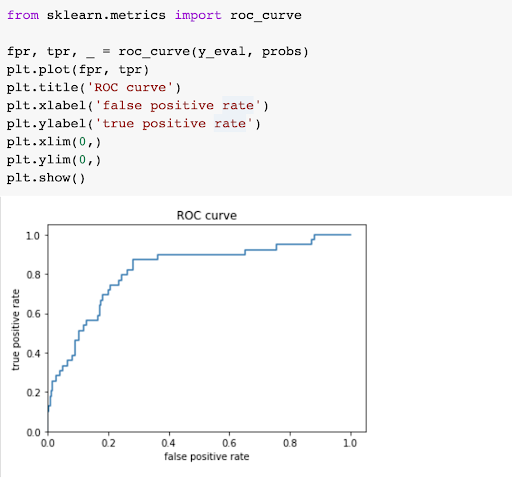
The ROC curve helps us see how quickly our model made improvements and is useful when attempting to prevent design issues with the model. The ROC chart plots the true positive rate against a false positive rate.
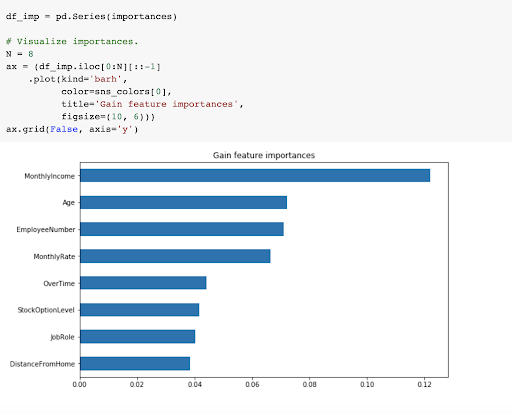
Now the Big Payoff. What are the factors that have the greatest impact on attrition? Finding these factors is the whole point. When we discover these, we can use the information to help guide our company:
Conclusion
Maybe there's more work to be done, but this is pretty successful for an initial exportation of the data set. We could probably start to use what we’ve found to address attrition!
I hope you enjoyed this brief tutorial of TensorFlow on Colab and that it enriches your programming skills and/or kick starts your ML career!



