
Last week, we discussed migrating an application that's on-premises to AWS. This time, we are going to talk about deploying serverless applications in AWS!
But wait, what does serverless mean? As explained in another of our Snippets posts dealing with telegram chatbots, serverless is a paradigm that allows us to build and run functions without having to deal with all the infra by using a cloud provider to host the functions and take care of everything for us. In AWS, this event-driven, serverless platform is known as "lambda".
AWS Lambda
 Imagine a huge variety of solutions available through a large selection of platforms--this is what you can do with lambda functions, especially now that it supports custom runtimes besides the official ones (you can find out more about this here).
Imagine a huge variety of solutions available through a large selection of platforms--this is what you can do with lambda functions, especially now that it supports custom runtimes besides the official ones (you can find out more about this here).
AWS Lambda charges per use and based on the amount of memory set, so it's important to build solutions that will take as little time as possible to run, and be aware of timeouts to avoid unexpected charges later, e.g. you'll incur extra charges if your function calls for an external service that's unavailable or if a large file is uploaded without its size being limited. Sometimes there are cases where we cannot escape extra time and charges, but knowing the implications of certain actions and implementing the functions with an understanding of how AWS Lambda works is the key for success.
Manual Deployment
Before going into the specs of automating the deployment, let's check how it works if we do it manually.
Below we have an example of a Node.js lambda function that's small enough that we can edit the code inline in the GUI console. Keep in mind that this may not be possible with certain package sizes or with runtimes such as Java.
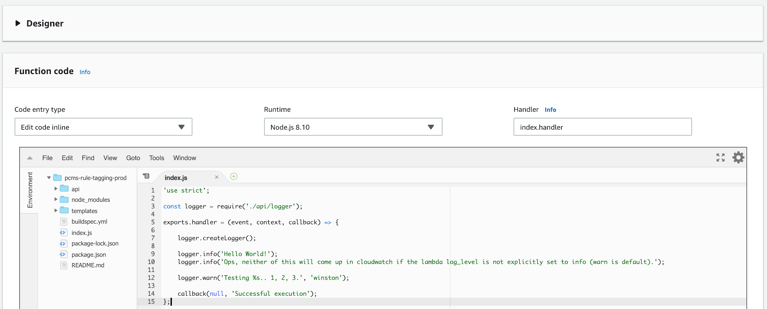
We can create and edit a lambda function, publish new versions, and define aliases to invoke them either via the console or by using your favorite IDE with an AWS SDK plugin. That's about all we have do to make the function available.
Furthermore, there are ways to "talk" to this function. These include merely invoking it from another lambda, cloudwatch rules to behave as a scheduled job, exposing with API Gateway endpoints, and more.
The example created for this article generates a simple API with POST method only. Similarly to the lambda function, this can be managed manually, as depicted in this console view:
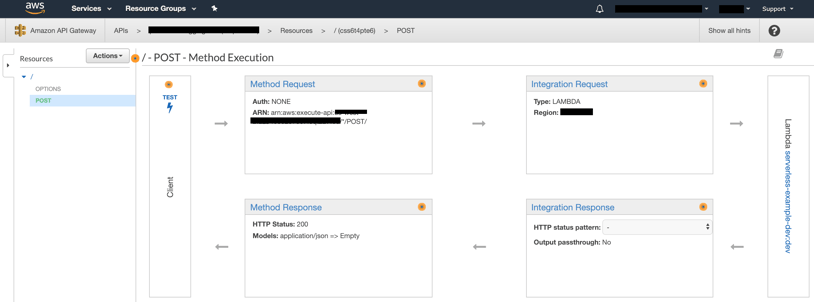
With the lambda function in place and the API Gateway endpoint properly configured, we have a service ready for use--imagine the possibilities!
Beyond simply exposing the API, AWS Lambda allows you to define authorizers for the endpoint, limit Lambda to work only on a private network, create tests to validate the code in the Lambda console, and test the API through the above GUI prior to deploying it to stages. All that and more make this quite a flexible solution.
CI/CD Automation
Finally, let's talk about the automation of our lambda function integration and deployment. This is very crucial not only for cases where the code changes often, but also for that disastrous moment when we delete a lambda function we manually created only for doing some tests and accidentally delete another function!
Okay, so the following represents the flow from a generic git repository, which will have the latest version of the code from a branch cloned and uploaded into S3. This will be the source used in the CodePipeline configured with build and deploy sections.
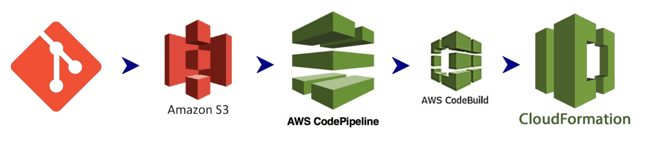 You may notice that this is similar to the flow described in our previous post. The difference is that these resources (CodePipeline and CodeBuild project) are all created via a CloudFormation template and the deploy section invokes a CloudFormation template too! How is that?
You may notice that this is similar to the flow described in our previous post. The difference is that these resources (CodePipeline and CodeBuild project) are all created via a CloudFormation template and the deploy section invokes a CloudFormation template too! How is that?
First, let's look at some examples of the flow for deploying lambda functions in AWS:
|
Standard CodePipeline
|
CodePipeline with an approval step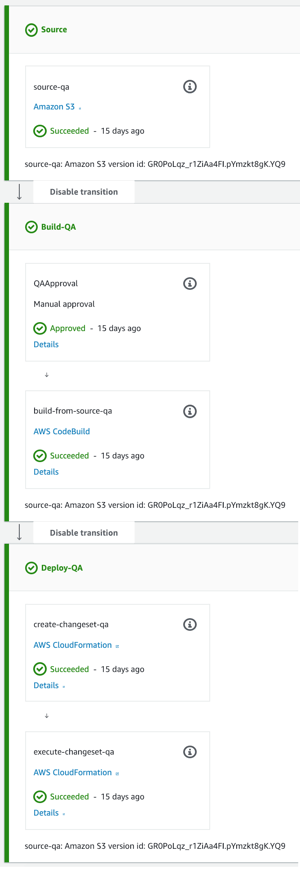 |
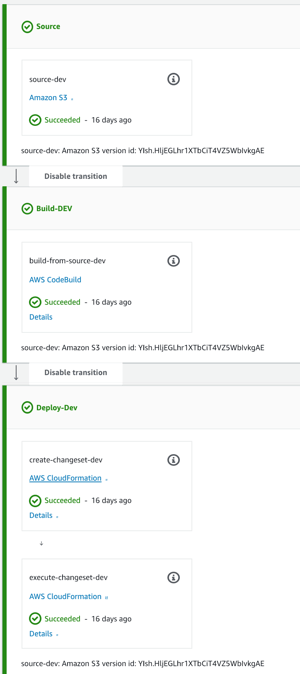
Unveiling the deploy mystery, the CloudFormation templates are there for creating any type of resource we need inside AWS, and that's no different for lambda functions and anything else we do with them. So first we use a template to create a pipeline and CodeBuild project that's unique to the application we're working on. Beyond this, we need another template, also known as a SAM file, that will be updated in the deploy section of the CodePipeline in every build/deploy to publish a new version of the lambda and update anything pointing to it to invoke the newest code. You can find more details on this here.
Wrapping Up
Below, you can see the structure of a simple Node.js lambda function and its underlying resources.
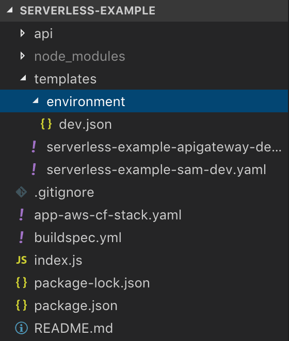 This is comprised of:
This is comprised of:
- the index.js with the entry point "handler(event, context, callback)";
- app-aws-cf-stack.yaml, the template used for creating the pipeline etc;
- buildspec.yml, which gives instructions for the CodeBuild project to run the build;
- templates/serverless-example-sam.., which is the cloudformation template used in the CodePipeline build section to publish the new lambda function version;
- templates/serverless-example-apigateway.., which is our swagger-formatted file invoked by the SAM above to instruct the API Gateway to create a new endpoint if there isn't one yet, or to update it if necessary.
You can view the source code for this example here.
That's all, folks! Now you know how to deploy an AWS serverless application. Thanks for reading, and please add comments, questions, and suggestions of your own below!



