
Welcome to the second part of our Snippets series on real-time stream processing using Apache Kafka! To recap, in part one we introduced stream processing and discussed some of the challenges involved, like the stateful nature of aggregations and joins. We’ll discuss the impact of such stateful operations in a while, but first, let’s delve deeper into one key aspect of real-time stream processing: performance.
Scalability
Of course, throughput will probably be the first thing that comes to mind when you think about real-time stream processing. As in other distributed systems, the best way to achieve this is by horizontally scaling stream processing to a large number of nodes. In Kafka, that’s what partitions are for: streams can be split into partitions (think shards in databases), and each record will be assigned to a partition based on a user-defined key. Behind the scenes, Kafka will distribute those partitions to brokers inside the Kafka cluster.
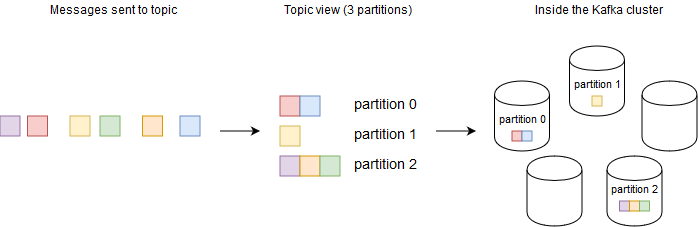
That takes care of scaling the backend, but one key thing to note is that Kafka Streams applications do not run inside the Kafka cluster; they just leverage default APIs to read and write to Kafka in very clever ways. Fortunately, scaling your stream processing application is easy: just run another instance of your application, and it’ll automatically join the taskforce to process incoming data. At any point in time, you can have as many active instances as there are partitions in the input streams your application is processing--and that’s one of the reasons why figuring out how many partitions to use is so important.
But let’s back up a bit. Why is it so easy to scale the stream processing application? Answering this question will give us more insight into how Kafka Streams work. The thing is, Kafka keeps track of all partitions in each input stream used by your application. As soon as an instance joins or leaves the processing efforts, Kafka will redistribute those partitions to the remaining instances. The default policy allocates one partition to a single instance/thread of your application. Kafka Streams will leverage threads for parallelism as well. And since we’re talking about exclusive access to a partition, the bulk of the work will be done coordination-free. The best kind of concurrency is none at all ;).
Finally, partitions naturally help with application availability since we won’t have a single point of failure, which brings us to the next problem to address in a real-time data pipeline.
Fault Tolerance
If you think about it, delays due to failures mean, from a business perspective, that we’re not achieving real-time stream processing at all. Fault tolerance is equally important, if not more important, due to the costs associated with diagnosis and recovery.
In the previous section, we went over partitions and mentioned how they can help with fault tolerance. That isn't enough, however: we can lose access to a considerable amount of data if a partition goes down. That's why Kafka also allows partitions to be replicated for the sole purpose of having a fallback (i.e. you can't read or write directly to them). If Kafka detects a partition leader is down, it’ll pick one in-sync replica and promote it to leader.
Do keep in mind that, by default, a partition leader will not wait for replicas to acknowledge writes, so there’ll be data loss if it fails after locally committing a write but before background synchronization happens. To enable durable writes, one has to force waiting for acknowledgments from a certain number of replicas before the write is considered done. That will, however, increase write latency.
Moving to a broader level, when it comes to High Availability, Kafka ships with MirrorMaker, an open source tool for replication. If an entire Kafka Cluster goes down, you can use a fallback cluster in another region that MirrorMaker kept in sync. There are also enterprise solutions available that focus on active-active replication, meaning geographically distributed clusters are also available for writes. In this scenario, one could also distribute the streaming application itself and expect low latency around the globe since it could use the nearby cluster for writes.
Recovery
Kafka has fault tolerance, but if our application goes down, how would that affect the real-time SLA?
Leaving fallback clusters aside, storage is extremely important to tackle this problem. But why would storage be such a big deal in real-time stream processing? Well, do you recall from the first part how we have stateful operations? And not only can failures happen, but the application is elastic, so instances can also come and go out of nowhere?
Those two together mean that if for whatever reason we need to migrate processing from one instance to another, we lose precious time already spent performing joins and aggregations (which, by the way, are usually the most expensive operations in Kafka Streams).
One way to solve this would be to store in-progress, stateful operations in centralized, durable storage. That way, if some other instance of our application needs to take over some aggregation, it can use the central storage to start where the previous one left off. Luckily, Kafka provides the durable storage we want.
First, Kafka is able to scale no matter how much data you store on it. Also, as we’ve just mentioned, writes can be made durable by forcing producers to await for replica acknowledgment. That, together with the fact that we can read data from any point in a topic, means Kafka provides the durability and flexibility we need.
For performance reasons, Kafka Streams also maintains local storage (by default the file system) that synchronizes changes to an internal topic our application will create. Keep in mind that Kafka, not the local storage, is the source of truth for stateful operations. If a single instance or even the entire stream application goes down catastrophically, losing all the local data, recovery instances can replay the internal topic to reconstruct their local state and resume processing.
Recovering local state can take some time depending on the application, so once again our real-time SLA would be affected. To fix this, you can configure local storage replication so that if processing fails at one node, another one replicating its local storage can assume it.
We still have to monitor and manage application uptime, but notice how the hard problem of performatively dealing with shared mutable state is solved by Kafka.
Recovering from Bugs
This is important to discuss, given the fact that topics are append-only. If a buggy application writes an incorrect record, it's impossible to delete it, so how can we fix this?
Let's use an example: Suppose we have an application aggregating some data to compute physical inventory quantity. At some point, an unanticipated edge case causes us to produce an impossible negative value. We can't delete that value, but remember our brief discussion of Kafka topics in the first part and how consumers have full control of their offsets? We can recover by fixing the calculation in our application and then making it move input topic offsets back to reprocess records. The next time our application picks the values that caused negative quantities, it'll produce the correct output.
An elegant fix, but there's more to it: we need to clear local storage and we need to move to the end of every intermediate topic Kafka creates. That way, when we reprocess our input, the correct values will come after the invalid ones.
Seems like a lot, no? Luckily, Kafka ships with a tool that makes things easier. It'll take care of pretty much everything, except removing local state and making sure downstream applications outside Kafka can deal with the temporary, invalid values. That last one is really up to us since whether we need to fix those applications or not will depend on their semantics.
Now that we’ve covered fault tolerance and recovery, it makes sense to talk about correctness. It turns out it’s not as easy as expected, and we’ll see why in the next couple sections.
Delivery Guarantee
No discussion about delivery and ordering guarantees is complete without this disclaimer:
If you’re lucky, your streaming application will be okay with duplicated records, in which case the default at-least-once delivery guarantee Kafka provides will work just fine. However, there are a bunch of common aggregations that will produce incorrect values in the face of duplicated records, like computing counts, sums, averages and so on.
In that case, it's best to switch to exactly-once-delivery, but some care must be taken. First, there’s a performance degradation associated with the stronger delivery guarantee; it should be slight, but it’s important to test the impact in your real-time data pipeline. Second, exactly-once-delivery requires coordination between all readers and writers involved, even external databases. The best way to achieve that is to make sure all processing happens inside Kafka, from the moment you read your inputs in the stream application all the way to inserting data in an external database.
If your streaming application depends on external systems outside the Kafka cluster, you’ll have to take extra care to make sure those systems' outputs will not cause the guarantee to be lost. Also, if you’re, say, writing the results of your real-time data pipeline to a relational database, you have to do so in a manner that writes to the database are kept in sync with your application position at any input stream. That is, your application pulls data from a bunch of input streams and then filters, maps and reduces it, but if in the end the external database transaction fails, the application has to make sure it doesn’t advance its position in any of the original input streams or the output streams created on top of them.
Sound tricky? That’s why the recommended approach is to use a Kafka Connector that supports exactly-once-delivery as well. Why try solving this hard problem by yourself if someone else already did it for you, right? Not only will the connector take care of moving the data in and out of external storage, but it also performs the required coordination to achieve exactly-once-delivery.
Ordering Guarantee
As with delivery guarantee, ordering in stream processing applications can range from unnecessary to explicitly required in order to compute aggregations correctly. Kafka does provide an ordering guarantee, but it's at the partition level and only if there’s a single writer for that partition (e.g. a single application instance).
A single application instance is an unlikely scenario since we need the parallelism to achieve real-time stream processing. In that case, ordering is still achievable, but it will be an application responsibility. For instance, by using the lower level Processor API inside Kafka Streams, you can buffer records locally and then write the outputs one at a time in any order you wish. Of course, it doesn’t make sense to sort an infinite amount of data, so this will require a windowed operation.
Another complicating factor is that the default Kafka configuration can produce records out of order, no matter the partition, if it has to retry sending a record (which it will, assuming default configuration). If a stream application first sends record A, followed by record B, we can get the order wrong in an output topic in the event that Kafka resends A due to a timeout. The configuration can be changed (see max.in.flight.requests.per.connection here), but it disables sending parallel write requests, so there’ll be a performance impact to measure.
Finally, it’s worth mentioning that order is based on offsets, the monotonically increasing number that keeps track of a stream application position in a stream. Order is not based on timestamps.
Conclusion
Kafka is a great tool that enables teams to do their own real-time stream processing with a low-entry barrier. A lower entry barrier, actually ;). I hope this Snippet managed to answer a few questions, but know that there are still a lot of important features, APIs, and tools that we haven’t covered: the Producer and Consumer API, the Connectors, KSQL, or just using Kafka as a messaging middleware.
If this has spiked your interest in Kafka, I encourage you to learn more about what it can do. In the meantime, feel free to ask any questions and to give your feedback in the comments.




